




Code LLMs Explained,
CodeBERT
CodeBERT is a pre-trained model developed by Microsoft Research, designed to understand and generate code in multiple programming languages as well as natural language text. It is based on the BERT (Bidirectional Encoder Representations from Transformers) architecture, which is a transformer-based model known for its success in natural language understanding tasks.
Model DetailsTechnical Experts

50 Custom AI projects
4.8 Minimum Rating
An Overview of CodeBERT
CodeBERT is a pre-trained model developed by Microsoft Research, designed to understand and generate code in multiple programming languages and natural language text.

CodeBERT achieved a mean average precision (MAP) of 0.428
Achieved 0.428 MAP
On a dataset of 100K Java methods, CodeBERT achieved a mean average precision (MAP) of 0.428, significantly higher than the previous state-of-the-art model.
Achieves SOTA performance code search and documentation.
SOTA performance
CodeBERT achieves SOTA performance in both natural language code search and code documentation generation, according to the results.
The first NL-PL model for 6 programming languages
6 programming languages
CodeBERT is the first large NL-PL pretrained model for multiple programming languages. On NLPL probing, the results show that CodeBERT outperforms previous pre-trained models.
Blockchain Success Starts here
About Model
CodeBERT is an advanced model created by Microsoft Research that comes pre-trained to comprehend and generate code written in various programming languages and natural language text. It leverages the BERT architecture, a transformer-based model with exceptional performance in natural language processing tasks. This enables CodeBERT to process code in a way that is similar to how humans read and understand natural language text. This means that it can perform tasks such as code retrieval, code generation, and code summarization with high accuracy and efficiency. With its ability to process multilingual code, CodeBERT is an invaluable tool for software developers, researchers, and practitioners who work with code in different languages.

Training Details
Training data
CodeBERT is trained on a large-scale dataset with 2.1 million bimodal data points and 6.4 million unimodal codes from six programming languages (Python, Java, JavaScript, PHP, Ruby, and Go). The data is derived from publicly accessible open-source GitHub repositories.


Training Procedure
CodeBERT is trained cross-modal, leveraging both bimodal NL-PL data and unimodal PL/NL data; it is pre-trained in six programming languages and trained with a new learning objective based on replaced token detection.
Training dataset size
CodeBERT was trained on a batch size of 2048, with a learning rate of 5e-4. FP16 was used to train CodeBERT on a single NVIDIA DGX-2 machine. It combines 16 NVIDIA Tesla V100 interconnected with 32GB memory.
Training time and resources
Training 1,000 batches of data takes 600 minutes with MLM and 120 minutes with RTD. The maximum length is set to 512, and the maximum training step is set to 100K.
| Model | Parameters | Highlight |
| CODEBERT (RTD) | Replaced Token Detection (RTD) | Replaces tokens with others from the same vocabulary to learn more contextual information and relationships. |
| CODEBERT (MLM) | Masked Language Modeling (MLM) | Randomly masks some tokens to predict them from the context of remaining unmasked tokens. |
| CODEBERT (MLM+RTD) | Both Masked Language Modeling and RTD | Combines MLM and RTD approaches for more effective learning and better performance on downstream tasks. |
| Task | Dataset | Score |
| natural language code retrieval | CodeSearchNet | 76 |
| PL Probing | CodeSearchNet | 85.66 |
| PL Probing with PRECEDING CONTEXT ONLY | CodeSearchNet | 59.12 |
| NL probing | CodeSearchNet | 74.53 |
| Code-to-Documentation generation | BLEU-4 | 17.83 |
| Code-to-NL | BLEU | 22.36 |
Benchmark Results
Benchmarking is an important process to evaluate the performance of any language model, including CodeBERT. The key results are;
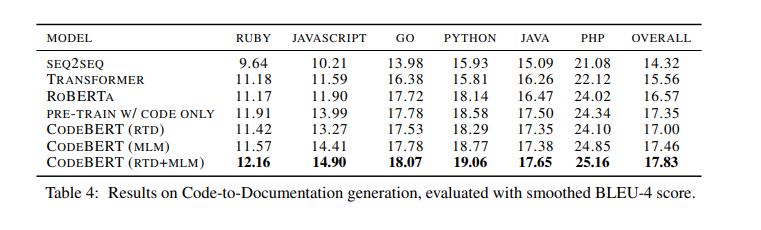
Table 4 shows the results with different models for the code-to-documentation generation task. As we can see, models pre-trained on programming language outperform RoBERTa, which illustrates that pre-trainning models on programming language could improve code-to-NL generation. Besides, results in Table 4 show that CodeBERT pre-trained with RTD and MLM objectives brings a gain of 1.3 BLEU score over RoBERTa overall and achieve the state-of-the-art performance.
Other LLMs

Polycoder
Polycoder is a deep learning model for multilingual natural language processing tasks
Read More

CodeGeex
CodeGeeX, a large-scale multilingual code generation model with 13 billion parameters pre-trained
Read More

CodeRL
CodeRL is a novel framework for program synthesis tasks that combines pretrained language models (LMs)
Read More