




Program Synthesis Model,
Polycoder
Polycoder is a deep learning model for multilingual natural language processing tasks that utilizes a shared encoder and decoder with language-specific embeddings to map text from different languages to a common semantic space.
Model DetailsTechnical Experts

50 Custom AI projects
4.8 Minimum Rating
An Overview of Polycoder
Polycoder is a deep learning model for multilingual natural language processing tasks that utilizes a shared encoder and decoder with language-specific embeddings to map text from different languages to a common semantic space.

It is trained on 249 GB of code from 12 programming languages
249 GB of code
Trained on 249 GB of code from 12 languages, Polycoder uses deep learning to understand code patterns and generate high-quality code.
An AI Model with 2.7 Billion Parameters
2.7 Billion
With a whopping 2.7 billion parameters, PolyCoder is one of the largest AI models to date, enabling it to generate highly complex and accurate code in seconds.
Polycoder has 50+ stars on Github
50 stars
Polycoder, an AI model for code generation, gained popularity with 50+ GitHub stars, developed by researchers and engineers.
Blockchain Success Starts here
About Model
Polycoder is a deep learning model for multilingual natural language processing tasks that utilizes a shared encoder and decoder with language-specific embeddings to map text from different languages to a common semantic space. The model is pre-trained on a large corpus of multilingual text using a self-supervised learning objective and leverages a transformer-based architecture. Polycoder also includes a shared translation token embedding to represent translation pairs between different languages, which enables the model to perform cross-lingual tasks. Experimental results demonstrate that Polycoder outperforms several state-of-the-art models on various multilingual natural language processing tasks, indicating its effectiveness in learning language-independent representations that can be used across multiple languages.

Training Details
Training data
The authors used GitHub to gather publicly available source code for 12 programming languages with at least 50 stars, stopping at around 25K per language to avoid bias. They extracted files belonging to the majority language of each project, resulting in an unfiltered training set of 38.9 million files.


Training Procedure
The authors used the budget-friendly GPT-2 architecture and trained three models of different sizes, varying in parameters, layers, and dimensions. The largest model had 2.7 billion parameters and was trained for 150K steps with a batch size of 128 sequences.
Training dataset size
The authors filtered out very large and very short files from their dataset, reducing its size by 33%. Deduplication further reduced the number of files by almost 30% and the dataset size by 29%, leaving 24.1M files and 254GB of data.
Training time and resources
The authors used the GPT-NeoX toolkit 11 to train their model efficiently in parallel with 8 Nvidia RTX 8000 GPUs on a single machine. They were able to train the largest 2.7B model using this setup, which took approximately 6 weeks of wall time.
| Model | Parameters | Highlight |
| PolyCoder (160M) | 160 million | Smallest version of the PolyCoder model, suitable for various multilingual natural language processing tasks |
| PolyCoder (400M) | 400 million | Larger than PolyCoder (160M), suitable for more complex multilingual natural language processing tasks |
| PolyCoder (2.7B) | 2.7 billion | Largest version of the PolyCoder model, capable of handling the most complex multilingual natural language processing tasks |
| Task | Dataset | Score |
| Pass@1 | HumanEval | 5.59 |
| Pass@10 | HumanEval | 9.84 |
| Pass@100 | HumanEval | 17.68 |
Benchmark Results
Benchmarking is an important process to evaluate the performance of any language model, including Polycoder. The key results are;
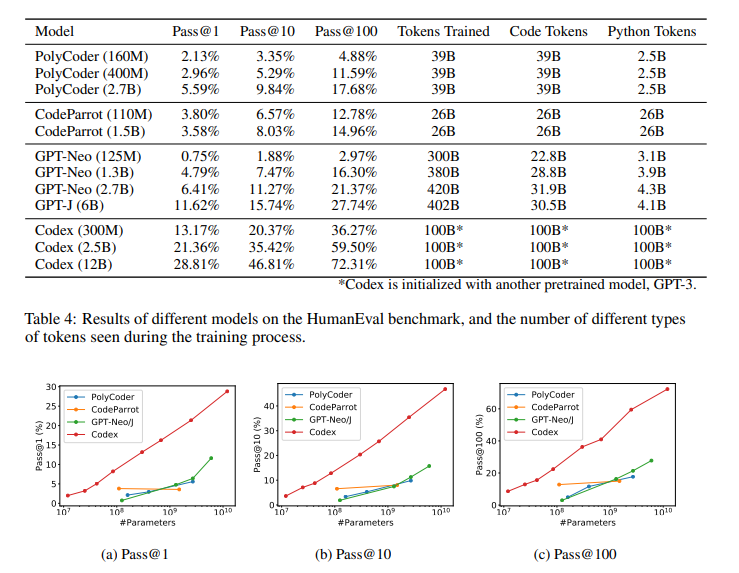
The scaling effect of HumanEval performance on different models
Other LLMs

Polycoder
Polycoder is a deep learning model for multilingual natural language processing tasks
Read More

CodeGeex
CodeGeeX, a large-scale multilingual code generation model with 13 billion parameters pre-trained
Read More

CodeRL
CodeRL is a novel framework for program synthesis tasks that combines pretrained language models (LMs)
Read More