




Code LLMs Explained,
SantaCoder
SantaCoder is a 1.1 B parameters program synthesis model pre-trained on Python, Java & JavaScript. The main model uses Multi Query Attention and it was trained for the Fill-in-the-Middle objective using near-deduplication and comment-to-code ratio as filtering criteria.
Model DetailsTechnical Experts

50 Custom AI projects
4.8 Minimum Rating
An Overview of SantaCoder
SantaCoder model was trained on GitHub code. It is not an instruction model, users should either phrase commands like they occur in source code or write a function signature and docstring and let the model complete the function body.

Model was trained with 1.1 Billion parameters on Java, JavaScript, and Python.
1.1 Billion Parameters
The base training dataset for the model contains 268 GB of Python, Java, and JavaScript files. Data removed opt-out requests, near-deduplication, and PII-redaction.
Santacode Model Trained with Multi Query Attention and Advanced Techniques.
Multi Query Attention
Multi Query Attention can significantly speed up inference for larger batch sizes, while fill-in-the-middle enables code models to do infilling tasks.
The model is trained with an enormous amount of 236 billion tokens
236 Billion tokens
The model was trained for Multi Query Attention and Fill-in-Middle with a total of 600,000 iterations, processing an enormous amount of 236 billion tokens during its training.
Blockchain Success Starts here
About Model
The SantaCoder models consist of multiple models with 1.1 billion parameters each, which were trained on a subset of The Stack (version 1.1) containing Python, Java, and JavaScript code. The main model utilized Multi Query Attention and was trained using near-deduplication and comment-to-code ratio as filtering criteria while using the Fill-in-the-Middle objective. Additional models were trained with variations in architecture and objective and using different filter parameters on different datasets. Despite being substantially smaller, the model obtains comparable or stronger performance than open-source, multilingual models, InCoder-6.7B and CodeGenMulti-2.7B, on code generation and infilling tasks on the MultiPL-E benchmark for three languages.

Training Details
Training data
The training dataset consists of Python, Java, and JavaScript files, totaling 268 GB in size, sourced from The Stack v1.1. The model was trained for Multi Query Attention and Fill-in-Middle with a total of 600,000 iterations, processing an enormous amount of 236 billion tokens during its training.


Training Procedure
The model is a 1.1B-parameter decoder-only transformer with FIM and MQA trained in float16. It has 24 layers, 16 heads, and a hidden size of 2048. The model is trained for 300K iterations with a global batch size of 192 using Adam g Adam with β1 = 0.9, β2 = 0.95, e = 10−8, and a weight-decay of 0.1.
Data Preprocessing
The model experimented the impact of 4 preprocessing methods on the training data: filtering files from repositories with 5+ GitHub stars, filtering files with a high comments-to-code ratio, more aggressive filtering of near-duplicates, and filtering files with a low character-to-token ratio.
Training Time and Resources
A total of 118B tokens are seen in training. The learning rate was set to 2 × 10−4 and followed a cosine decay after warming up for 2% of the training steps. Each training run takes 3.1 days to complete on 96 Tesla V100 GPUs for a total of 1.05 × 1021 FLOPs.
| Task | Dataset | Score |
| Multi Query Attention (FIM) | HumanEval | 0.34 |
| Multi Head Attention | HumanEval | 0.37 |
| Multi Query Attention | HumanEval | 0.37 |
| Multi Query Attention (FIM) | MBPP | 0.61 |
| Multi Head Attention | MBPP | 0.64 |
| Multi Query Attention | MBPP | 0.62 |
| left-to-right (pass@100) | HumanEval | 0.45 |
| fill-in-the-middle (line filling, exact match) | HumanEval | 0.55 |
| Python docstring generation | BLEU Score | 18.13 |
Benchmark Results
Benchmarking is an important process to evaluate the performance of any code LLM, including SantaCoder. The key results are;
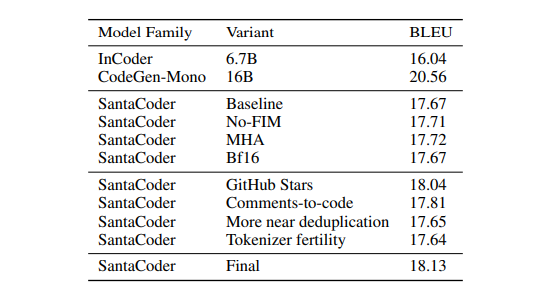
CodeXGLUE (Lu et al., 2021) Python Docstring generation smoothed 4-gram BLEU scores using the same methodology as Fried et al. (2022) (L-R single). Models are evaluated zeroshot, greedily and with a maximum generation length of 128.
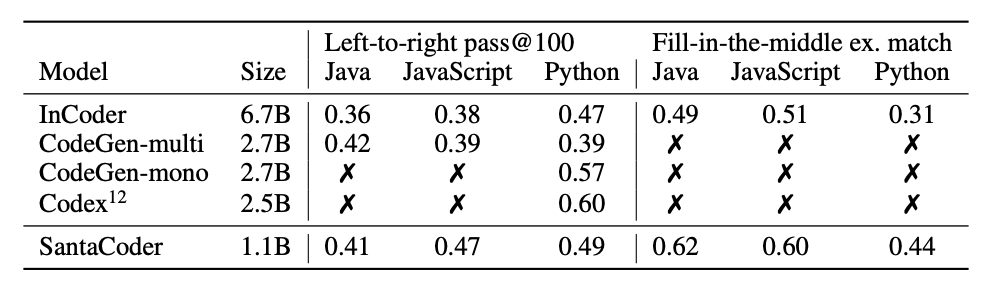
Comparing the performance of the final version of SantaCoder with InCoder (Fried et al., 2022), CodeGen (Nijkamp et al., 2022), and Codex (Chen et al., 2021) on left-to-right (HumanEval pass@100) and fill-in-the-middle benchmarks (HumanEval line filling, exact match).
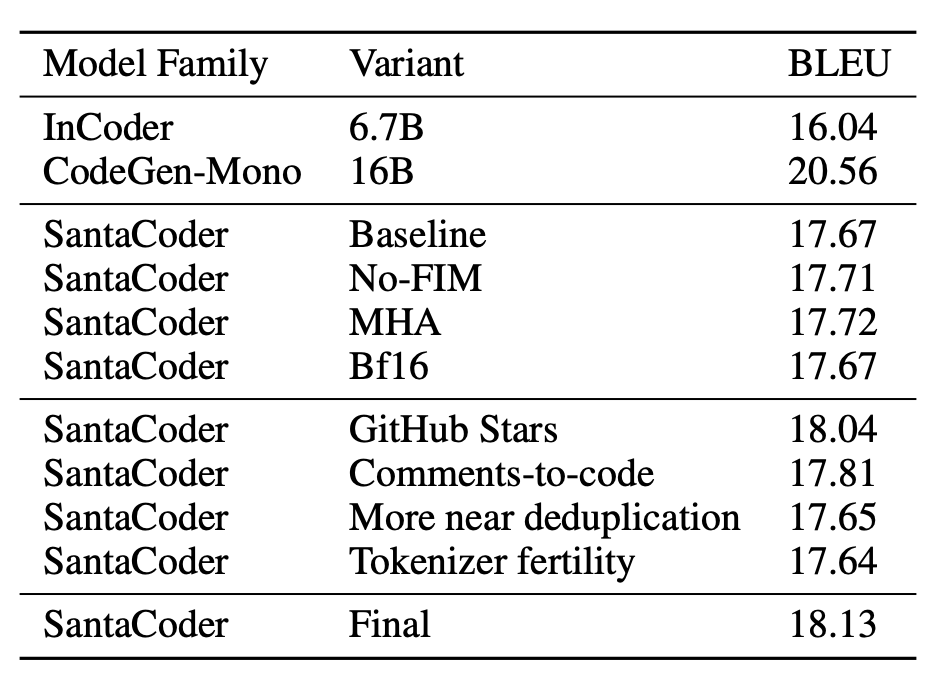
CodeXGLUE (Lu et al., 2021) Python Docstring generation smoothed 4-gram BLEU scores using the same methodology as Fried et al. (2022) (L-R single). Models are evaluated zeroshot, greedily and with a maximum generation length of 128.
Other LLMs

Polycoder
Polycoder is a deep learning model for multilingual natural language processing tasks
Read More

CodeGeex
CodeGeeX, a large-scale multilingual code generation model with 13 billion parameters pre-trained
Read More

CodeRL
CodeRL is a novel framework for program synthesis tasks that combines pretrained language models (LMs)
Read More