



T2I Models Explained,
DeepFloyd
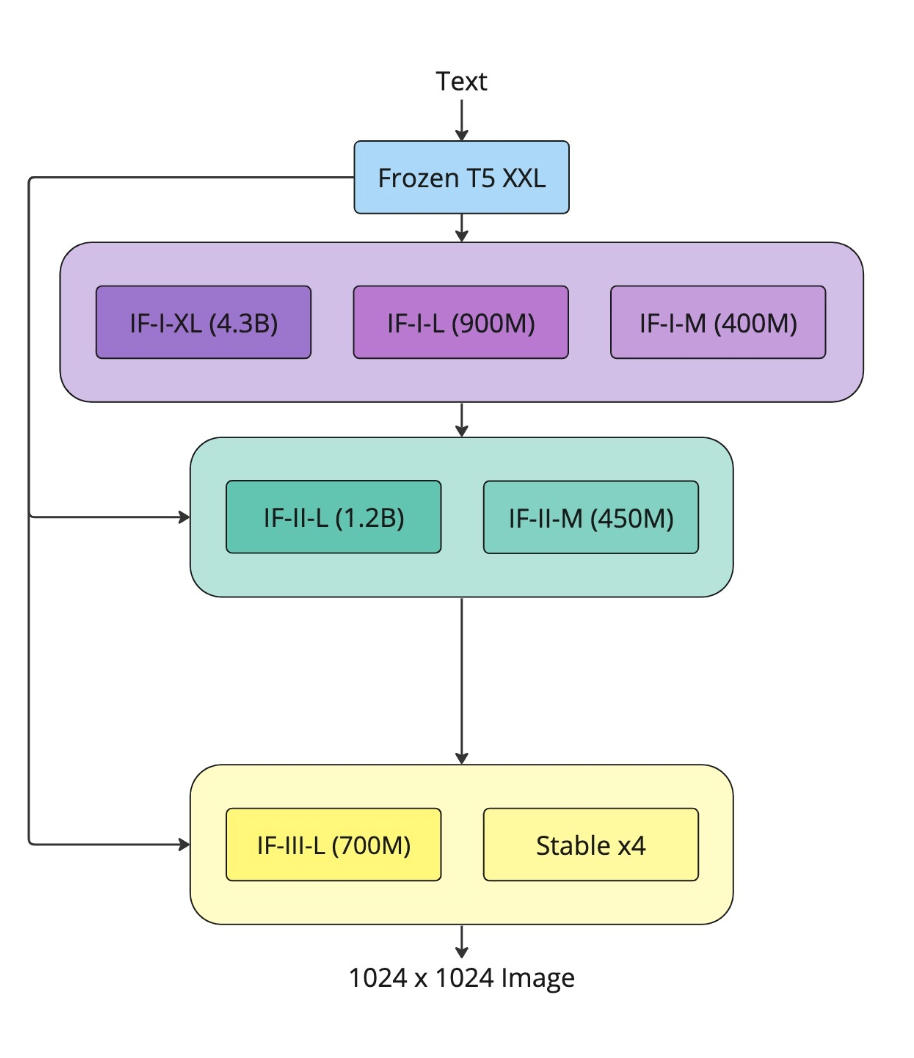
DeepFloyd-IF is an advanced text-to-image diffusion model that excels in both photorealism and language comprehension. It achieves impressive results, surpassing existing models in terms of efficiency and performance. Specifically, it achieves a remarkable zero-shot FID-30K score of 6.66 on the COCO dataset. DeepFloyd-IF is designed as a modular system, consisting of a frozen text mode and three pixel cascaded diffusion modules. These modules generate images at progressively higher resolutions: 64x64, 256x256, and 1024x1024. The model employs a frozen text encoder, based on the T5 transformer, to extract text embeddings. These embeddings are then utilized in a UNet architecture, which incorporates cross-attention and attention-pooling techniques for enhanced image generation.
Model Card100+ Technical Experts

50 Custom AI projects
4.8 Minimum Rating
Blockchain Success Starts here
About Model
The researchers introduce DeepFloyd IF, an advanced open-source text-to-image model known for its impressive photorealism and language understanding. DeepFloyd IF is designed as a modular system consisting of a text encoder that remains unchanged and three-pixel diffusion modules that work in a cascaded manner. The base model generates 64x64 px images based on the provided text prompt. It is then followed by two super-resolution models designed to generate images of increasing resolution: 256x256 px and 1024x1024 px.
The entire model utilizes a frozen text encoder based on the T5 transformer. This encoder extracts text embeddings, which are then passed through a UNet architecture enhanced with cross-attention and attention pooling. Combining these components results in an efficient model surpassing existing state-of-the-art models. It achieves a remarkable zero-shot FID score of 6.66 on the COCO dataset, highlighting its exceptional performance.
The findings of this research emphasize the potential of utilizing larger UNet architectures in the initial stage of cascaded diffusion models. It also provides a glimpse into a promising future for text-to-image synthesis.
Developed by: DeepFloyd Lab at StabilityAI
License: DeepFloyd IF License Agreement
- IF is designed with a collaborative approach, incorporating multiple neural modules that work together within a single architecture to achieve a synergistic effect. The model follows a cascading approach to generate high-resolution images. It starts with a base model that produces low-resolution samples, further enhanced by a series of upscale models to create visually stunning, high-resolution images.
- The base model and the super-resolution models in IF utilize diffusion models, which employ Markov chain steps to introduce random noise into the data. This process is then reversed to generate new data samples from the noise, resulting in improved image quality. Unlike latent diffusion techniques like Stable Diffusion, which rely on latent image representations, IF operates directly within the pixel space. This approach allows for more precise manipulation and generation of images.
- Transitioning from the shadows to the light, image-to-image translation can now be accomplished through a simple yet effective process. By resizing the original image to 64 pixels and introducing a controlled amount of noise using forward diffusion, followed by denoising the image with a fresh prompt during the backward diffusion process, remarkable transformations can be achieved.
- IF demonstrates a remarkable affinity for text, skillfully incorporating it into various artistic mediums. Whether it's embroidering text onto fabric, integrating it into a stained-glass window, including it in a collage, or illuminating it on a neon sign, IF excels in these challenging text-to-image scenarios. Previous text-to-image models have faced difficulties in achieving such versatility, making IF a pioneering solution in this regard.

Example

Other LLMs

PFGM++
PFGM++ is a family of physics-inspired generative models that embeds trajectories for N dimensional data in N+D dimensional space using a simple scalar norm of additional variables.
Read More

MDT-XL2
MDT proposes a mask latent modeling scheme for transformer-based DPMs to improve contextual and relation learning among semantics in an image.
Read More

Stable Diffusion
An image synthesis model called Stable Diffusion produces high-quality results without the computational requirements of autoregressive transformers.
Read More