

Hey everyone, it’s your AI specialist from Accubits back again! We’re all witnessing the incredible power of Generative AI, but as many are discovering, that power comes with a formidable price tag. As pressure mounts from boards and investors to demonstrate a clear ROI on AI initiatives, cost management has evolved from a technical concern into a C-suite priority. When a business decides to build or integrate a GenAI solution, they’re essentially making two distinct types of financial commitments, a classic CapEx vs. OpEx scenario defined by the crucial balance of GenAI inference vs training costs.
The media loves to focus on the headline-grabbing multi-million dollar training costs for huge models. While significant, these are just two of several hidden factors that drive GenAI costs. But for most businesses, the real budget killer isn’t the one-time mountain of training; it’s the relentless, ever-flowing river of inference costs that can silently erode profitability over time. So, the crucial question for any leader is: when you look at GenAI inference vs training costs, where should you focus your optimization efforts?
In this in-depth guide, we’ll dissect this crucial financial balance. We will cover:
The high upfront costs and optimization strategies for AI Training.
A breakdown of the five most common traps where businesses overspend.

Training is the process of creating the model itself. It’s where the magic begins, and it’s by far the most resource-intensive phase in the AI lifecycle. This is the stage where you feed a neural network vast quantities of data, allowing it to learn patterns, structures, and concepts until it becomes a powerful, generalizable tool.
The astronomical price tag of training from scratch is driven by a trifecta of expensive components:
The iterative nature of research and development adds another significant layer of expense. Training isn’t a single, clean run. It involves countless experiments, hyperparameter tuning, and often, failed attempts. A single multi-week training run can cost hundreds of thousands of dollars in compute time. If the resulting model doesn’t meet performance benchmarks, that entire cost is sunk, and the process must begin again. This makes AI training cost reduction not just a matter of efficiency, but also of critical risk management.
For 99% of businesses, the smartest way to optimize training costs is to avoid doing it from scratch. The goal is to stand on the shoulders of giants who have already made the massive upfront investment.
If training is building the factory, inference is the 24/7 production line. Inference is the process of using the trained model to make predictions, generate text, or create images for your end-users. Every time a user interacts with your AI feature, an inference request is made, and it costs you money. This is the operational side of AI, and its costs are ongoing and directly proportional to your success.
The danger with inference costs lies in their incremental nature. Each individual query might cost a fraction of a cent, which seems negligible. But this is the classic “death by a thousand cuts.” When you scale to millions or even billions of queries per month, those fractions of a cent aggregate into a massive operational expense. A key technical driver here is not just compute time, but also memory. Large models must be loaded into the VRAM of expensive GPUs, and the cost of keeping this high-bandwidth memory powered and “hot” 24/7 is a significant and often overlooked component of the final bill.
This leads to the “success tax”: the more popular your product becomes, the more your inference bill explodes. This scalability issue can catch businesses completely off guard, turning a profitable product into a money-losing one as it grows. The debate over GenAI inference vs training costs often ends here, as ongoing inference costs almost always dwarf the initial training investment over the lifecycle of a product.
AI inference optimization is a game of marginal gains that have a massive impact at scale. The goal is to make every single query as efficient as possible.
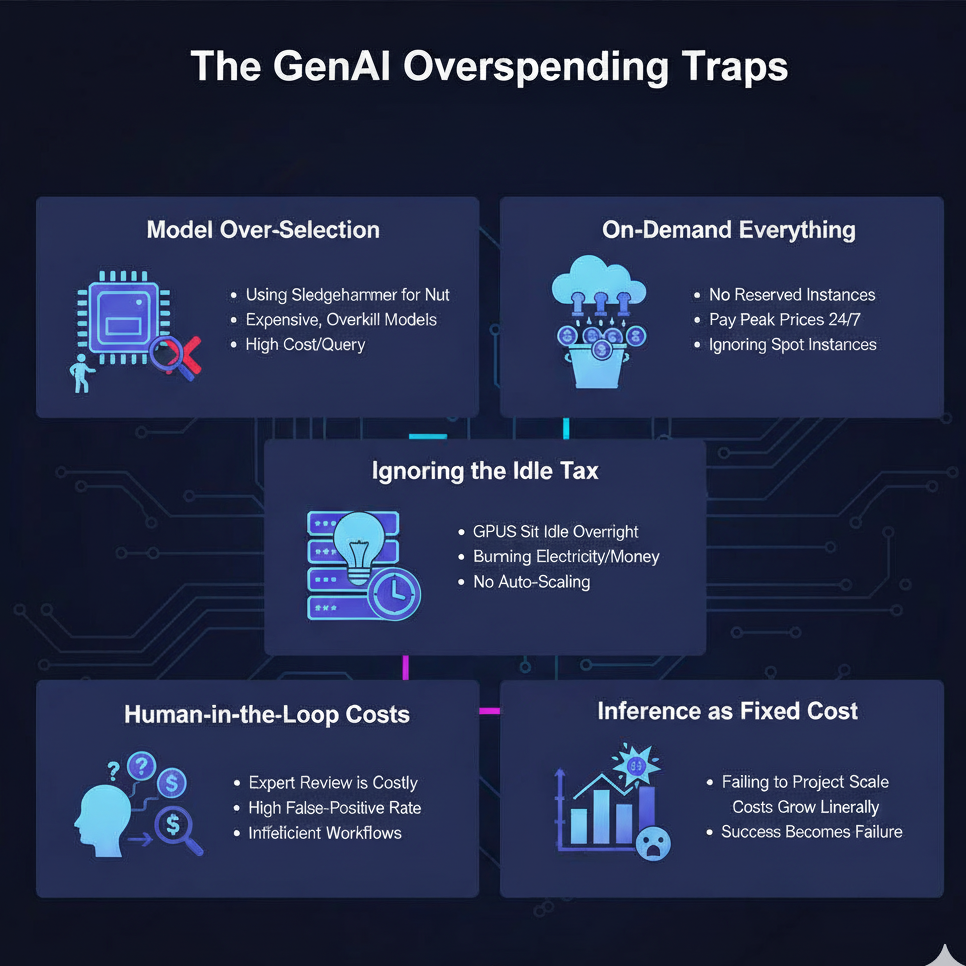
After analyzing dozens of AI projects, we’ve seen the same costly mistakes repeated time and again. Many of these mistakes stem from a fundamental misunderstanding of GenAI inference vs training costs, leading companies to misallocate their resources. Here is an in-depth breakdown of where most companies overspend.
This is the single biggest and most common mistake. A company needs a chatbot to answer simple questions about its product documentation. Instead of using a smaller, specialized model, they opt for a powerful, general-purpose API from a major provider. While this model is incredibly capable, it’s massive overkill. The cost-per-query is 10-20x higher than necessary, and the latency is often worse.
Real-World Example: Imagine a popular cafe in Thiruvananthapuram wanting to build a WhatsApp bot to answer questions like “Are you open now?” or “Do you have fresh banana chips today?”. Using a massive, state-of-the-art model for this is like hiring a rocket scientist to be a cashier. A single query to a top-tier API might cost a small amount, but a self-hosted, fine-tuned 7-billion-parameter model could answer the same query for a hundredth of the cost. The overspend here is purely on paying for capabilities that are never used.
Many teams fall into the trap of using expensive, on-demand GPU instances for all their needs because it’s the easiest option. They use the same high-priced instances for experimentation, predictable production traffic, and batch processing. This is like paying peak taxi fares for your daily commute, your weekend trips, and your airport runs. A smart GenAI cost breakdown involves a portfolio approach to compute. Use highly discounted Reserved Instances for your stable, predictable production inference workload. Use deeply discounted Spot Instances for interruptible tasks like model evaluation or batch jobs. On-demand instances should only be used for bursting capacity or unpredictable, short-term needs. Ignoring this strategy means you’re likely overspending on your cloud bill by 40-70%.
To ensure low latency, many companies keep a fleet of powerful GPU servers running 24/7. However, user traffic is never constant; it has peaks and troughs. This means that for large parts of the day (especially overnight), those expensive GPUs are sitting idle, burning electricity and costing you money while doing nothing. This “idle tax” is a huge hidden cost. The solution is to use auto-scaling infrastructure. Technologies like Kubernetes with KEDA (Kubernetes Event-driven Autoscaling) or serverless GPU platforms can automatically scale your number of active GPUs up or down based on real-time demand, even scaling down to zero during idle periods. This ensures you only pay for the compute you are actively using.
A frequently overlooked but massive expense is the human cost associated with AI. Many high-stakes applications—in fields like medical diagnostics, legal tech, or financial compliance—cannot be fully automated. They require a human expert to review, correct, or approve the AI’s output. This introduces a significant, ongoing human operational cost that is directly tied to the AI’s inference quality.
Real-World Example: Consider an AI tool designed to assist radiologists in a hospital in Kochi. The AI scans an X-ray and flags potential anomalies for review (this is the inference cost). However, a senior radiologist must then personally review every single flag. If the model is poorly tuned and has a high false-positive rate, the situation is disastrous. The digital inference cost is wasted on junk alerts, and the much higher cost of the expert radiologist’s time skyrockets as they are forced to manually sift through hundreds of false alarms, reducing their overall productivity. This is a critical factor where poor AI inference optimization directly inflates human operational expenses.
This is a classic budgeting failure. A company builds a proof-of-concept with 1,000 beta users and calculates their monthly inference cost to be a manageable $500. They secure funding and launch publicly. Six months later, they have 500,000 users. They are shocked when their inference bill isn’t slightly higher; it’s now $250,000 per month. They failed to understand that inference is a variable cost that scales linearly with usage. When creating a business model for an AI product, the projected cost of inference at scale must be a primary input. Failing to do this is one of the fastest ways for a successful product to become a financial disaster.
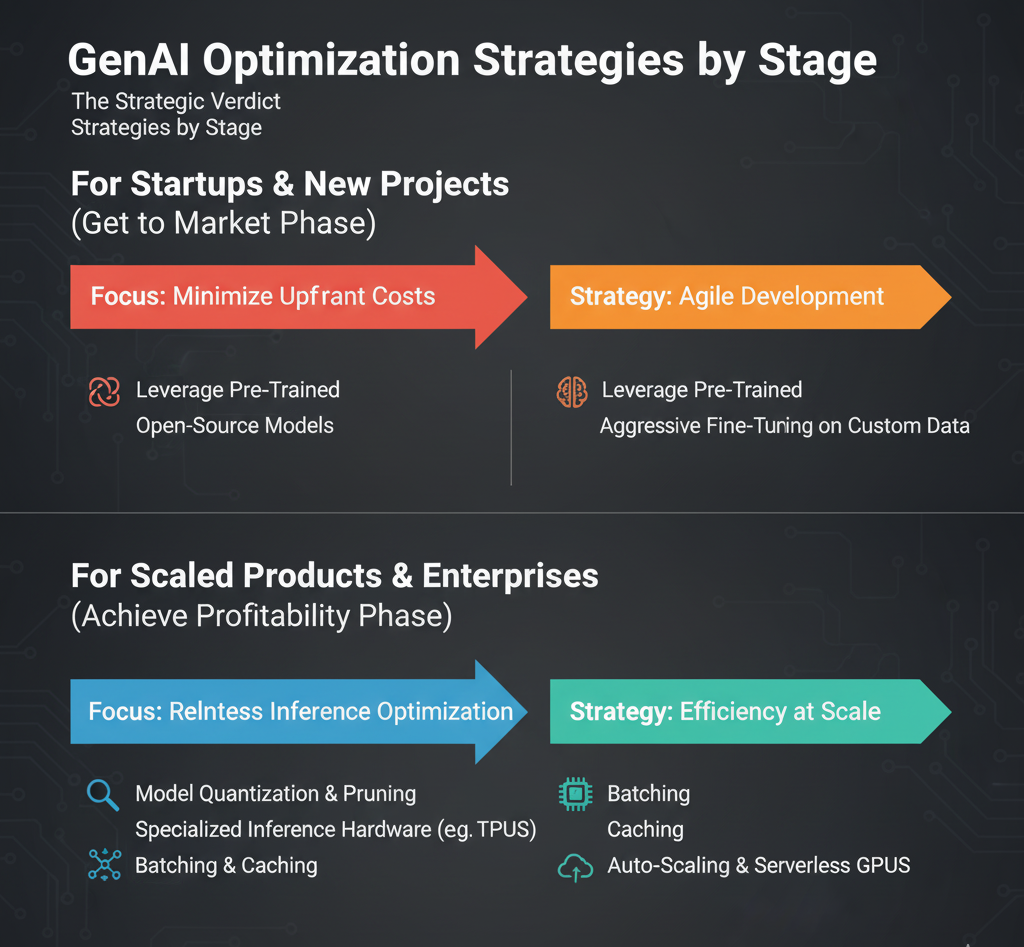
So, returning to the central question of GenAI inference vs training costs, where should you focus? The answer depends entirely on your stage of development, and it’s a dynamic cycle.
For Startups & New Projects (The “Get to Market” Phase): Your focus should be almost 100% on reducing training costs. Your primary goal is to develop a Minimum Viable Product (MVP) as quickly and cheaply as possible. This means avoiding training from scratch at all costs.
For Scaled Products & Enterprises (The “Achieve Profitability” Phase): Once you have a product in the market with significant user traffic, your focus must pivot dramatically to relentless AI inference optimization. At this stage, your ongoing inference bill will dwarf your initial training investment.
It’s important to note this isn’t a one-time switch. As a product matures, you will enter a cycle. You’ll need to periodically fine-tune your model on new data to prevent drift, which is a small-scale training cost. But the insights from your inference monitoring will guide this process, ensuring you’re only re-training when necessary. The scale of investment, however, remains firmly shifted toward continuous, marginal inference improvements.
Thinking about GenAI inference vs training costs is best summarized with an analogy: training is the steep, difficult mountain you must climb once to reach the summit. Inference is the vast, unpredictable ocean you must then navigate every single day, forever.
While the climb is daunting, it’s a finite challenge that can be made dramatically easier by choosing the right path (fine-tuning). The real, ongoing challenge is navigating the ocean of operational costs efficiently without sinking your budget. In today’s competitive market, a proactive cost management strategy is a significant advantage, allowing you to scale sustainably while others are forced to pull back due to runaway expenses. Smart optimization isn’t about choosing one over the other; it’s about applying the right strategies at the right time.
Navigating this complex financial and technical landscape is a challenge. Here at Accubits, we specialize in helping businesses develop a balanced cost optimization strategy for the entire AI lifecycle, from efficient model development to highly-optimized, scalable deployment. If you’re ready to build powerful AI solutions that are also profitable, get in touch with our experts today.
