

Hey everyone, it’s your tech team at Accubits! Over the past few weeks, we’ve explored the hidden factors that drive AI costs and the tools you can use to monitor them. Theory is crucial, but nothing demonstrates the power of smart optimization like real-world proof. Today, we’re moving from the “how” to the “how it’s done” with a practical GenAI cost reduction case study.
Many businesses are currently facing the “AI cost paradox”: the more successful their AI-powered feature becomes, the more its operational costs threaten to erode their profit margins. It’s a classic scaling challenge that can turn one of the many brilliant business applications of GenAI into a financial liability. This was the exact situation facing “FinScribe,” a promising Bengaluru-based FinTech startup, before they decided to tackle the problem head-on.
This article provides a transparent, step-by-step breakdown of the strategies we helped FinScribe implement. It’s a journey that ultimately led them to a 40% reduction in their monthly GenAI API spend, all while maintaining the quality their customers had come to expect. This is their GenAI cost reduction case study.
In this case study, we’ll walk you through:
To understand the solution, you first need to appreciate the problem. FinScribe wasn’t a company that was careless with its spending; it was a victim of its own success, a common story for fast-growing tech companies in hubs like Bengaluru and across India.
FinScribe’s core product is “InsightEngine,” a B2B SaaS platform designed for investment firms and financial analysts. The tool is brilliant in its simplicity: it allows a user to upload a lengthy, complex financial document like a 100-page quarterly earnings report or an IPO prospectus and within minutes, it generates a concise summary, identifies key financial metrics, performs sentiment analysis on the management’s tone, and flags potential undisclosed risks.
To achieve the highest possible quality and accuracy from day one, FinScribe’s founders made a common and understandable decision: they built their entire engine on top of OpenAI’s most powerful and capable model, GPT-4. They believed that using the best model would give them a competitive edge and ensure customer satisfaction. For every task, from the simplest sentiment check to the most complex risk analysis, they used the best tool on the market. In the early days, this worked perfectly. The quality was superb, their initial clients were thrilled, and their reputation for providing high-quality insights grew.
The problem began when the company started to scale. Their pricing model was a standard monthly subscription fee, but their cost model was purely variable. As their client base grew, their API costs grew in perfect lockstep, exposing them to the financial and legal implications of third-party APIs.
The numbers told a frightening story:
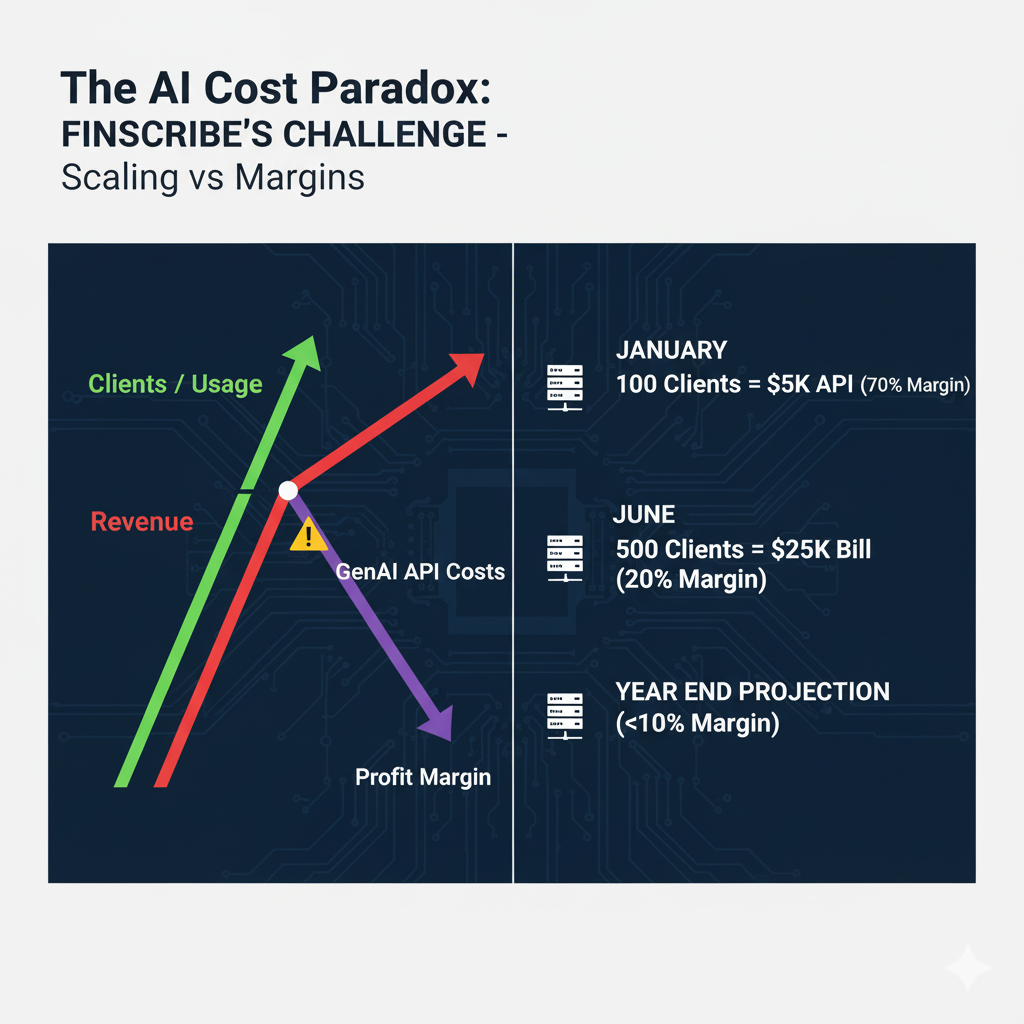
This wasn’t just a line item on a spreadsheet; it became a point of contention in strategic meetings. The CFO began to question the long-term viability of the entire ‘InsightEngine’ product line, asking how they could ever achieve profitability if their core cost scaled directly with their customer base. The CTO, in turn, defended the technology choice, arguing that the quality of the model was their primary market differentiator. It became clear that without a new approach, their most innovative feature would become their biggest liability, putting a cap on their growth potential. This linear cost scaling was destroying their unit economics. A healthy 70% gross margin on their core feature had plummeted to under 20%, and it was still falling. They needed a plan to optimize LLM costs, and they needed it fast.
The solution wasn’t about finding a single magic bullet or simply switching to a cheaper provider. It required a holistic audit of FinScribe’s entire GenAI pipeline, a system that differs greatly from other types of AI systems. Our approach was to treat their AI usage like a supply chain, identifying and eliminating inefficiencies at every step of the process. This is a core tenet of a successful AI FinOps strategy.
We focused our investigation on three core areas:
The initial hypothesis here was that the single-model approach was the biggest cost driver. An early audit of their API logs proved this correct in spectacular fashion. We discovered that simple sentiment analysis and data extraction tasks accounted for nearly 70% of their total API calls, yet they were paying the premium GPT-4 price for every single one. This immediately became our top priority. Was the most powerful model truly necessary for every single task? Or were they using a sledgehammer to crack a nut, a common issue when teams are not guided on choosing the right LLM for the job?
How lean were their API calls? Our initial analysis of their prompt logs showed that the average prompt length was inflated by over 30% due to conversational filler, verbose instructions, and a lack of format constraints. Each of these unnecessary tokens, when multiplied by millions of calls, was contributing thousands of dollars to their monthly bill. The team needed to shift from treating prompts as simple questions to engineering them as efficient instructions.
Were they doing the same work over and over again? Log analysis quickly revealed that the top 10 most popular financial reports (from major public companies) accounted for over 20% of their total processing volume. This meant they were repeatedly paying to summarize the exact same documents for different clients. This identified aggressive caching as a clear and high-impact solution to prevent redundant API calls.
By breaking the problem down into these three pillars, we could develop a multi-pronged strategy. This wasn’t about a single change but about a series of compounding optimizations that, together, would lead to significant AI cost savings and a powerful GenAI cost reduction case study.s that, together, would lead to significant AI cost savings and a powerful GenAI cost reduction case study.
After a thorough audit, we implemented four key changes to FinScribe’s “InsightEngine.” Each one targeted a specific inefficiency we had uncovered.
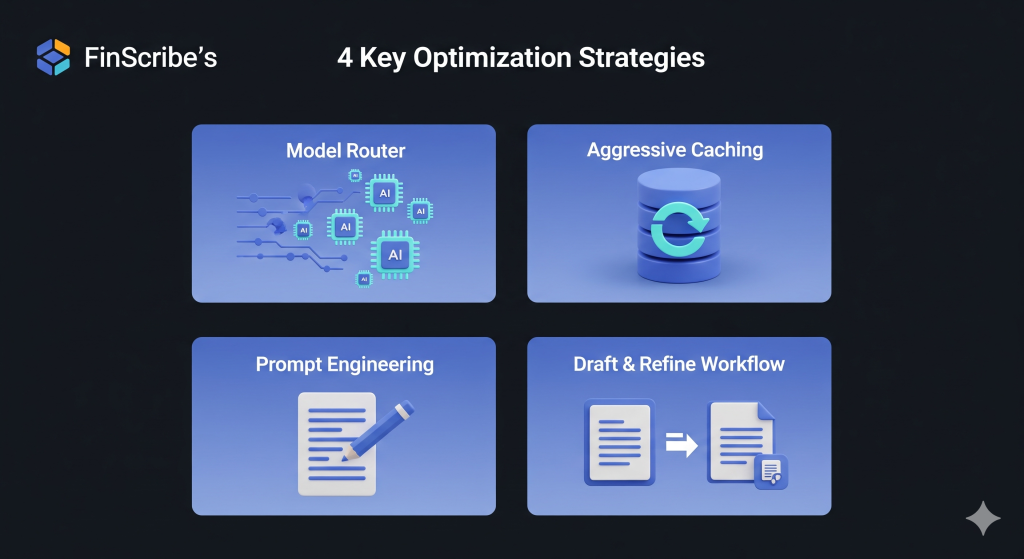
The Problem: FinScribe was using the expensive GPT-4 for every single task. This included simple positive/negative sentiment analysis, medium-complexity summarization, and truly complex contextual risk identification.
The Solution: We designed and implemented a “model router.” This is a piece of logic at the start of their workflow that assesses the complexity of the task and routes the routes the request to the most cost-effective model for the job, a decision that requires a deep understanding of different model capabilities.
Technical Nuances: The selection of these models wasn’t arbitrary. We conducted a rigorous benchmarking process where we tested each candidate model against a “golden dataset” of 500 real-world examples for each task. We measured not only the accuracy but also the cost and latency. For sentiment analysis, Haiku achieved 99% of GPT-4’s accuracy at less than 5% of the cost. This data-driven approach gave the FinScribe team the confidence that they could reduce costs without a noticeable drop in quality for their simpler tasks.
The Impact: This was the single most effective change. Since the simpler tasks accounted for the majority of their token volume, this intelligent routing immediately slashed their blended cost-per-document. This step alone was responsible for a 25% reduction in their overall API spend.
The Problem: Many of FinScribe’s clients were analyzing the same popular public documents. Their system was processing the same 100-page PDF from scratch dozens of times, incurring the full, expensive cost for each analysis.
The Solution: We implemented an aggressive caching layer using Redis, a high-speed in-memory database. The new workflow was simple:
Technical Nuances: The key to success here was achieving a high “cache hit ratio.” We chose to use a content-based hash (SHA-256 of the file’s contents) as the cache key. This ensured that even if a file was uploaded with a different name, as long as the content was identical, it would be served from the cache. We set a Time-To-Live (TTL) of 24 hours on each cached item to ensure freshness while still capturing the benefit of repeated requests within the same day.
The Impact: This eliminated roughly 15% of their total API calls, leading to a further 10% cost reduction on top of the savings from the model router. As a bonus, it made the user experience feel instantaneous for popular documents.
The Problem: FinScribe’s early prompts were conversational and their API calls didn’t specify an output length. This resulted in prompts that used more input tokens than necessary and responses that were often more verbose (and thus more expensive) than required.
The Solution: We workshopped their entire prompt library, a key discipline in prompt engineering for cost savings.
max_tokens parameter to strictly define the desired length of summaries and other outputs.Technical Nuances: The change in prompt design was dramatic. For instance, their original summary prompt was, "Could you please act as a financial analyst and provide a detailed summary of the key findings in the attached report?". The revised, optimized prompt was: "Summarize the key financial findings from the following text. Respond ONLY in a JSON object with the key 'summary'. Do not add any introductory or concluding text. Text: ". This direct, format-constrained prompt reduced input tokens and, more importantly, slashed output tokens by ensuring the model’s response was nothing but pure, structured data.
The Impact: These changes reduced the average number of tokens per API call by over 20%, contributing another 5% to their total savings.
The Problem: For their highest-tier clients, FinScribe wanted to offer an exceptionally nuanced “premium” summary. Their only tool for this was to run the entire document through GPT-4, which was very expensive.
The Solution: We introduced an asynchronous, two-step “draft and refine” workflow.
Technical Nuances: A key part of this implementation was managing the user experience for an asynchronous task. When a user requested a premium analysis, the UI would immediately confirm the request and inform them that their in-depth report was being generated and would be ready in 2-3 minutes. They would receive an email and an in-app notification when it was complete. This managed user expectations and turned the processing delay into a feature of a “deeper” analysis.
The Impact: This clever workflow allowed them to leverage the power of GPT-4 for the final polish without paying for it to process the entire source document. It enabled a new premium feature tier while keeping costs under control.
The cumulative effect of these four initiatives was transformative for FinScribe’s business. The numbers speak for themselves:
The breakdown of the savings that made this GenAI cost reduction case study so impactful was clear:
This GenAI cost reduction case study proves that significant savings are achievable without compromising the quality of the end product. The full potential of these technologies can be explored in various business applications of GPT-3. It’s about working smarter, not cheaper.
This GenAI cost reduction case study provides a powerful blueprint for any company looking to get its GenAI ROI under control. The key lessons are universal:
Ultimately, GenAI cost optimization is not a one-time project; it’s the continuous process of building an efficient and intelligent “AI supply chain,” ” a concept top industry analysts at firms like Gartner are closely monitoring.
FinScribe’s journey is a powerful example of what’s possible with a strategic approach to AI budget management. If your AI bills are scaling faster than your revenue, it’s time for an optimization audit. Contact the experts at Accubits, and let’s build your own GenAI cost reduction case study.
