

Hey everyone, and welcome back to the Accubits blog! We’re living through a massive technological shift. Generative AI is reshaping industries with a speed that’s hard to comprehend, with adoption rates more than doubling in just a few years. Companies are racing to integrate this tech to boost innovation and efficiency, and for good reason—the potential is enormous. But here’s the reality check the product demos often leave out: this power comes with a significant price tag. Many businesses, captivated by the promise of Generative AI, dive in headfirst, only to be sideswiped by a cloud bill that can derail their entire budget. The initial development cost is just the tip of the iceberg. To achieve a positive ROI, you must understand the full spectrum of Generative AI cost factors.
Without this clarity, you risk overspending on the wrong infrastructure, underinvesting in critical optimizations, and building a solution that is financially unsustainable. The challenge is that the most significant expenses—in compute cycles, data transfer fees, and ongoing maintenance—are often hidden. In this deep dive, we’re pulling back the curtain to reveal the eight critical, and often overlooked, Generative AI cost factors every leader and developer needs to understand. Let’s get into it.
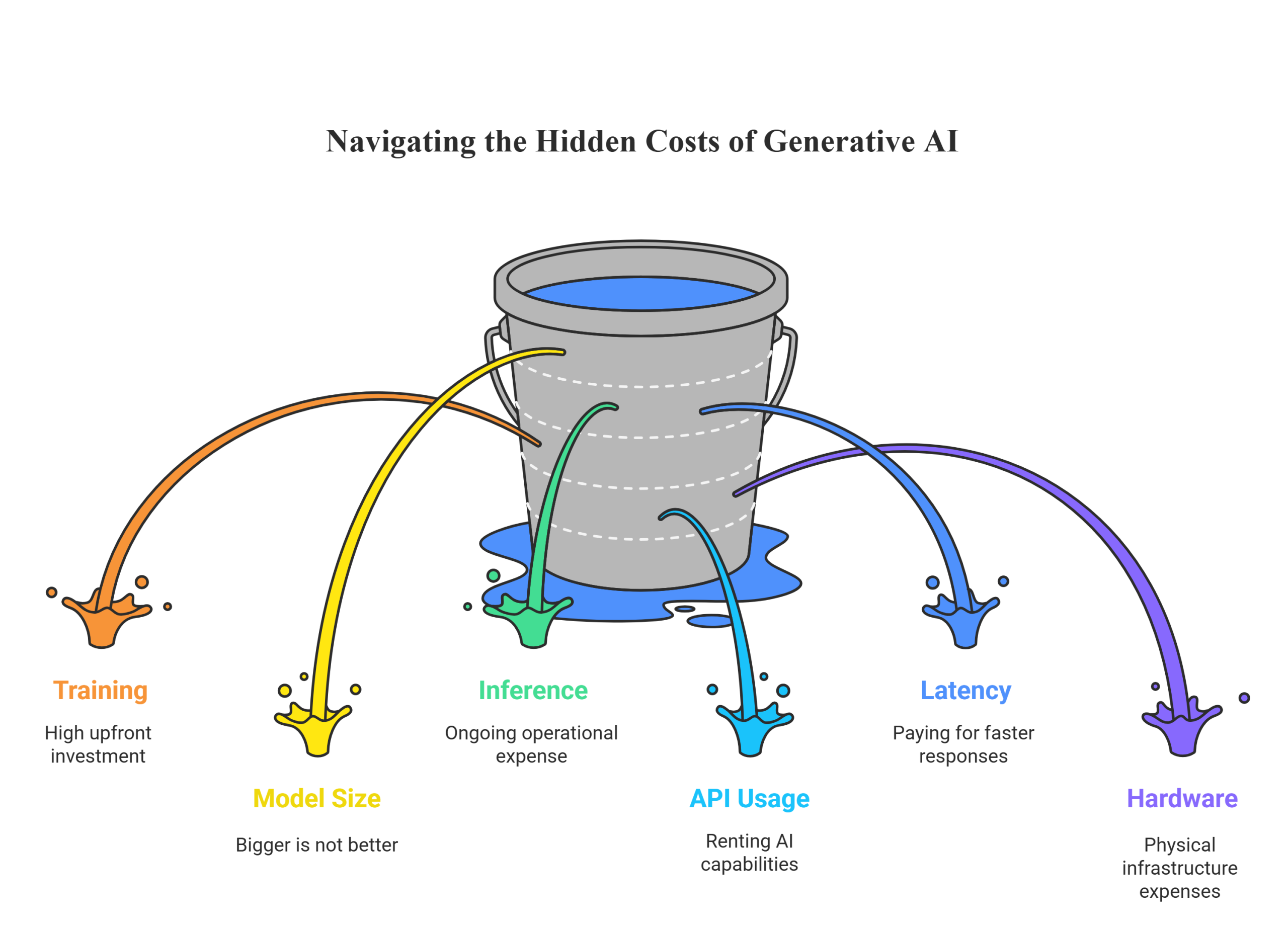
When people think about AI expenses, their minds often go straight to the initial training. AI training expenses represent the single largest upfront investment in any custom Generative AI project. This is the process of teaching a model by feeding it vast amounts of data, allowing it to learn patterns and relationships. It’s an incredibly resource-intensive phase, consuming massive amounts of computational power from specialized GPUs for weeks or even months. The cost is driven by compute time, data, and talent. For perspective, training a model like GPT-3 was estimated to cost millions of dollars in compute power alone.
However, the most overlooked cost is often data preparation. Raw data is messy, and teams can spend up to 80% of their time cleaning, labeling, and structuring datasets before training can even begin. This human-intensive labor is a massive hidden expense. Furthermore, not all training runs succeed, meaning you might spend a fortune on a failed experiment and have to start over.
In the early days of the LLM arms race, the number of parameters was a key metric, leading to a “bigger is better” mentality. While larger models can capture more nuance, their scale comes at a steep, often unnecessary, cost. Model size is one of the most fundamental Generative AI cost factors because it directly impacts nearly every other expense, from training duration to the hardware needed for deployment.
A larger model requires more data, longer training times, and more powerful hardware to run. A model with 175 billion parameters can’t operate on a standard server; it needs a cluster of expensive, high-memory GPUs. For many business applications, like a chatbot for product documentation, using a massive general-purpose model is overkill. A company can often fine-tune a much smaller, specialized model that would be faster, significantly cheaper to run, and potentially even more accurate for its specific task. This choice alone can make a 10-20x difference in ongoing operational costs.
If training is the upfront cost, inference is the ongoing operational expense of using the AI. AI inference costs are incurred every time your model makes a prediction or generates content. This is a critical factor because it scales directly with your product’s success—more users mean more queries and a higher bill. While the cost of a single inference call is a fraction of a cent, millions of daily queries can quickly turn into a multi-million-dollar operational line item.
The hidden danger of inference costs is their direct relationship with user engagement. A product that goes viral can see its inference bill explode overnight, potentially bankrupting a startup that didn’t plan for success. Another hidden factor is the cost of underutilized capacity, where expensive GPUs must run 24/7 to handle peak traffic, even when they are idle. This is a crucial area to monitor when analyzing your Generative AI cost factors.
For many companies, the most accessible route to GenAI is using a pre-trained model via an API from providers like OpenAI, Anthropic, or Google. This converts a massive capital expense into a manageable operational one. The cost structure is typically based on “tokens” (pieces of words), where you pay for both the input and the output. While the per-token cost seems tiny, the API costs for AI can add up incredibly fast for applications that process large volumes of text.
The convenience of APIs makes this a popular choice, but it comes with hidden strategic costs. The most significant is vendor lock-in; building your product around one provider’s API makes it very difficult to switch. There are also potential data privacy concerns, as you’re sending your data to a third party. Finally, you have less control over pricing changes, rate limits, and model updates, which can impact your application unexpectedly.
Latency, the delay between a request and an AI response, is a critical feature for interactive applications. Low latency is essential for a good user experience, but achieving it is a significant, often hidden, driver of Generative AI costs. To minimize delay, you need to run your model on high-performance hardware and keep it “hot” and ready 24/7. This means you can’t power down resources during quiet periods, forcing you to pay a premium for constant readiness.
The hidden cost of high latency isn’t just on your cloud bill; it’s in lost revenue. A customer will abandon a sales chatbot that feels slow and unnatural. Conversely, an application that generates weekly reports can tolerate high latency, allowing it to run on cheaper, non-urgent infrastructure. Mismatching your application’s latency needs with its infrastructure is a common and expensive error. Properly balancing speed and cost is a key part of reducing AI infrastructure costs.
Ultimately, AI runs on physical hardware. The AI hardware requirements are a massive cost driver, whether you buy it yourself (CapEx) or rent it from the cloud (OpEx). The market is dominated by powerful but expensive GPUs from companies like NVIDIA, with a single high-end card costing more than a luxury car. Building an on-premise cluster requires a multi-million dollar investment not just in GPUs, but also in high-speed networking, memory, and storage.
If you build on-premise, the hidden costs are staggering. These machines consume enormous amounts of electricity and require industrial-grade cooling systems, leading to massive utility bills. You also have to factor in the cost of the data center space, physical security, and the IT staff needed for maintenance. For most companies, these hidden operational costs make renting from a cloud provider a much more financially sound decision and a primary strategy for reducing AI infrastructure costs.
For most businesses, the cloud is the default platform for Gen AI. However, the complexity of cloud pricing models makes Gen AI cloud costs a silent budget killer. The bill you receive is often a surprise, filled with line items you never considered. Beyond the hourly rate for a GPU instance, you are charged for:
These combined charges make managing Gen AI cloud costs one of the most important tasks for any AI team.
AI models are not static; they require constant maintenance and improvement. This ongoing effort, managed by an MLOps (Machine Learning Operations) team, is one of the most underestimated Generative AI cost factors. The core problem is model drift: as the real world changes, a model trained on old data becomes less accurate. To combat this, you must continuously monitor performance and periodically re-train the model on new data.
The most significant hidden cost here is the people. Experienced MLOps engineers are in high demand and command high salaries. Building the automated pipelines for monitoring, testing, and deployment is a major investment. Neglecting this ensures your initial investment will slowly become obsolete, a far greater cost in the long run. Properly accounting for this lifecycle is key to optimizing generative AI expenses.
Your Cost Optimization Playbook
Navigating the complex landscape of Generative AI cost factors requires a strategic approach. Here is a practical checklist to help you get started.
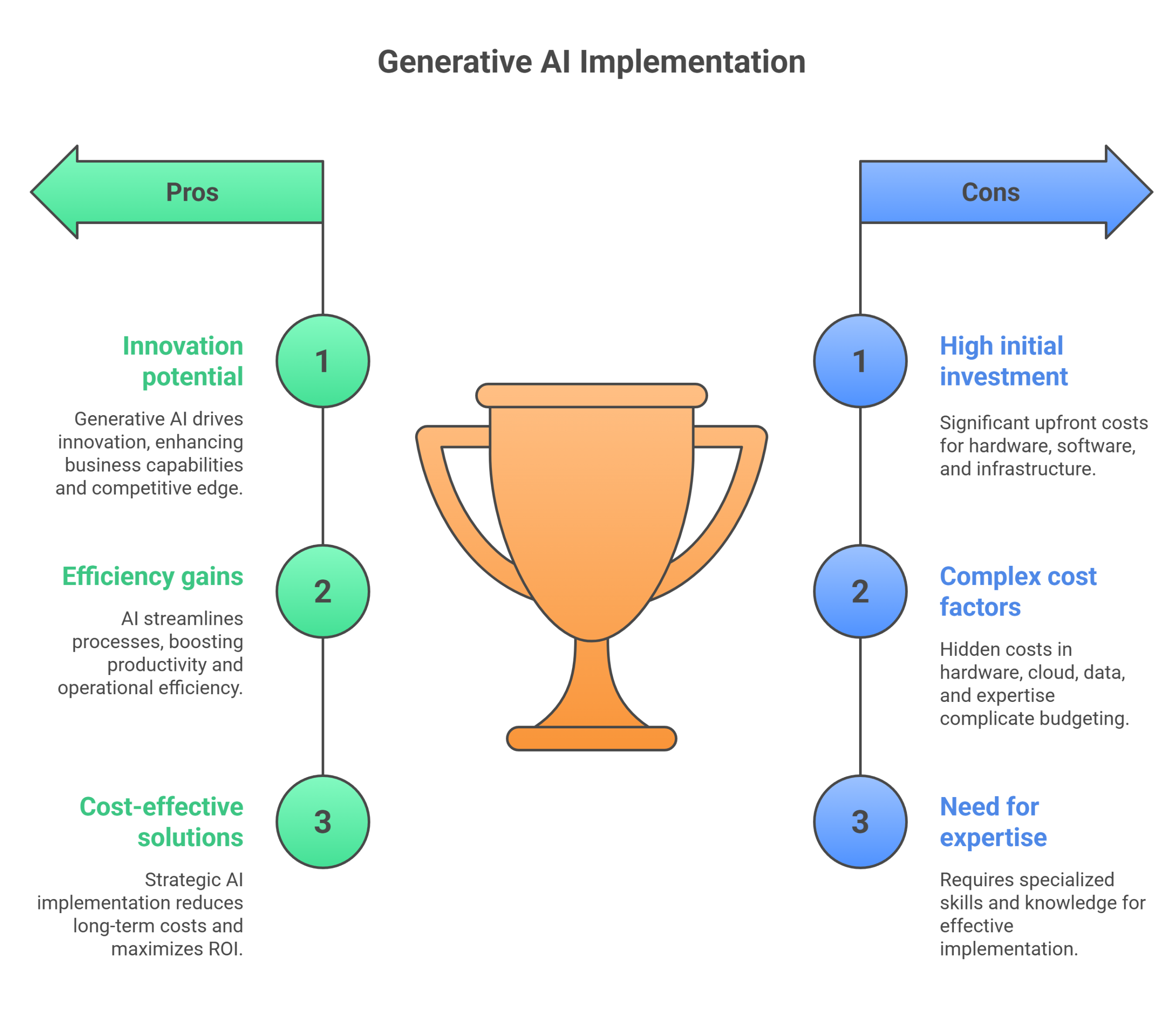
The world of Generative AI is powerful, but it’s not a free lunch. The total cost of ownership is a complex interplay of hardware, cloud services, data, and human expertise. Understanding these eight hidden Generative AI cost factors is the most critical step toward success. By approaching your initiatives with a cost-aware mindset, you can make smarter decisions and build systems that are not only technologically impressive but also financially viable.
Navigating this intricate landscape can be daunting. If you’re looking to harness the power of GenAI without falling victim to its hidden costs, you need an expert partner. Here at Accubits, we specialize in designing and optimizing cost-effective Generative AI solutions that maximize performance and protect your bottom line.
Ready to build smarter? Contact our AI experts today and let’s turn your Generative AI vision into a profitable reality.
