




T2I Models Explained,
Stable Diffusion
An image synthesis model called Stable Diffusion produces high-quality results without the computational requirements of autoregressive transformers. It represents the state-of-the-art in class-conditional image synthesis and super-resolution. It can model complex distributions of natural images without requiring trillions of parameters because it is built from denoising autoencoders.
Model Card100+ Technical Experts

50 Custom AI projects
4.8 Minimum Rating
An Overview of Stable Diffusion
The Stable Diffusion is an image synthesis model that produces high-quality results in class-conditional image synthesis and super-resolution.

Stable Diffusion, a image synthesis model has been made open-source by Stability AI.
1.1 Billion Parameter
Stable Diffusion, a state-of-the-art image synthesis model that uses a 1.1 billion-parameter latent diffusion model.
Stable Diffusion has been pretrained and fine-tuned on the LAION dataset.
5B Image Dataset
The stable Diffusion model is pretrained and fine-tuned on the LAION 5-billion image dataset to generate high-quality images.
Training the existing model on a specific dataset for just 30 minutes.
Image Variations
Dolly's language processing capabilities are improved through a fine-tuning process that involves training on a specific dataset for just 30 minutes.
Blockchain Success Starts here
About Model
Stable Diffusion, a text-to-image neural network, creates pixel-level attribution maps using the DAAM text-image attribution method. The method's generalized attribution quality and semantic segmentation were both assessed. The research paper analyzed interaction patterns on head-dependent heat maps and investigated the function of syntax in the pixel space. According to research that examined semantic phenomena such as feature entanglement, Cohyponyms had a detrimental effect on generation quality. This analysis offers fresh perspectives on large diffusion models when viewed from the standpoint of visuolinguistics.

Training Details
Training data
The authors randomly sampled 200 words from each of the 14 most common part-of-speech tags in COCO, as extracted with spaCy, to construct their word-image dataset. This resulted in 2,800 word-prompt pairs.


Training dataset size
Stability AI recently open-sourced Stable Diffusion, a 1.1 billion-parameter latent diffusion model, pretrained and fine-tuned on the LAION 5-billion image dataset.
Training Procedure
Stable Diffusion 2.0 base model (512 by 512 pixels) with 30 inference steps, the default 7.5 classifier guidance score, and the state-of-the-art DPM solver.
Training time and resources
The Stable Diffusion paper authors have not provided sufficient information regarding the dataset size and training time.
| Task | Dataset | Score |
| Image Generation | COCO-Gen | 64.7 |
| Image Generation | COCO-Gen | 59.1 |
| Image Generation | COCO-Gen | 60.7 |
| Image Generation | COCO-Gen | 59 |
| Image Generation | COCO-Gen | 55.4 |
| Image Generation | Unreal-Gen | 58.9 |
| Image Generation | Unreal-Gen | 60.8 |
| Image Generation | Unreal-Gen | 58.3 |
| Image Generation | Unreal-Gen | 57.9 |
| Image Generation | Unreal-Gen | 52.5 |
| Tasks | Business Use Cases | Examples |
| Denoising | Improving the quality of noisy text data | Cleaning up OCR scanned documents, removing noise from speech recognition transcripts, enhancing low-quality images and videos |
| Image Generation | Creating synthetic data for computer vision models | Generating new product images for e-commerce, creating realistic images of non-existent products or environments for marketing |
| Instance Segmentation | Object detection and segmentation in visual data | Identifying specific objects in satellite or drone imagery, detecting objects in medical scans, identifying individuals in CCTV footage |
| Semantic Segmentation | Identifying objects in images based on their semantic meaning | Self-driving cars identifying objects on the road, identifying parts of a medical image for diagnosis, classifying land use in satellite imagery |
| Text-to-Image Generation | Creating visual representations of text-based data | Generating images for social media posts or articles, creating visual aids for presentations or reports |
| Unsupervised Semantic Segmentation | Identifying patterns and relationships in text data | Clustering similar documents or sentences together, identifying topics or themes in a large corpus of text, identifying key phrases or entities in text data for NLP tasks. |
Benchmark Results
Benchmarking is an important process to evaluate the performance of any language model, including Stable Diffusion. The key results are;
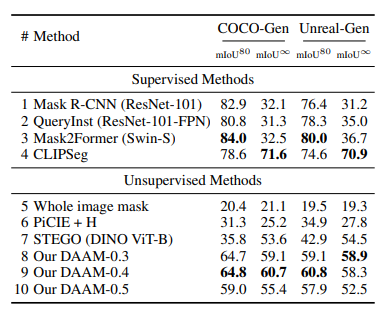
Table 1: MIoU of semantic segmentation methods on our synthesized datasets. Best in each section bolded.
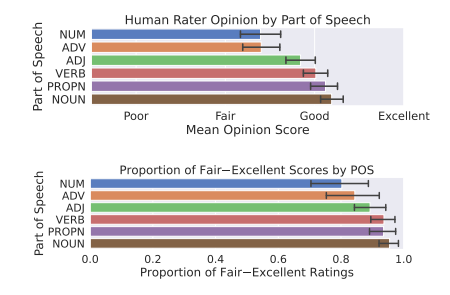
Figure 3: On the top, mean opinion scores grouped by part of speech, with 95% confidence interval bars; on the bottom, proportion of fair–excellent scores, grouped by part-of-speech.

Figure 4: Example generations and DAAM heat maps from COCO for each interpretable part-of-speech.
Other LLMs

PFGM++
PFGM++ is a family of physics-inspired generative models that embeds trajectories for N dimensional data in N+D dimensional space using a simple scalar norm of additional variables.
Read More

MDT-XL2
MDT proposes a mask latent modeling scheme for transformer-based DPMs to improve contextual and relation learning among semantics in an image.
Read More

Stable Diffusion
An image synthesis model called Stable Diffusion produces high-quality results without the computational requirements of autoregressive transformers.
Read More