




T2I Models Explained,
StyleGAN-XL
StyleGAN-XL is a new image synthesis model that sets a record by generating high-resolution images at 1024*1024 pixels. Its efficient training strategy allows for a larger model with less computation than prior models and can generate images beyond portraits and specific objects. Despite being three times larger than standard models, it can still match the performance of prior models with far less training time.
Model Card100+ Technical Experts

50 Custom AI projects
4.8 Minimum Rating
An Overview of StyleGAN-XL
StyleGAN-XL is a new image synthesis model that sets a record by generating high-resolution images at 1024*1025 pixels. Its efficient training strategy allows for a larger model with less computation than prior models and can generate images beyond portraits and specific objects.

StyleGAN-XL outperforms BigGAN on ImageNet
Gets 13.5 PSNR
Using basic latent optimization, StyleGAN-XL achieves a PSNR of 13.5 on average for inversion on the ImageNet validation set at 512x512, outperforming BigGAN at a PSNR of 10.8.
State-of-the-art performance at a higher resolution
512*512 pixels
Training StyleGAN-XL to match prior state-of-the-art performance on a 512x512 image resolution takes 400 days on a single NVIDIA Tesla V100 GPU.
Model trained on a total of 220 million images
220 Million
The authors trained the model on a total of 220 million images, significantly larger than the datasets used in previous state-of-the-art models.
Blockchain Success Starts here
About Model
StyleGAN-XL is a new image synthesis model that sets a record by generating high-resolution images at 1024*1024 pixels. Its efficient training strategy allows for a larger model with less computation than prior models and can generate images beyond portraits and specific objects. Despite being three times larger than standard models, it can still match the performance of prior models with far less training time.

Training Details
Training data
The model is trained on a diverse set of datasets, including ImageNet, LSUN, and YFCC100M. The datasets are first preprocessed to improve consistency and remove low-quality images.


Training dataset size
The authors trained the model on a total of 220 million images, significantly larger than the datasets used in previous state-of-the-art models.
Training Procedure
The authors introduce an efficient progressive, growing strategy that enables large-scale training while maintaining stability.
Training time and resources
The authors used a total of 512 NVIDIA V100 GPUs to train the model for approximately 9 days.
| Task | Dataset | Score |
| Image Generation | CIFAR-10 | 1.85 |
| Image Generation | FFHQ 1024 x 1024 | 2.02 |
| Image Generation | FFHQ 256 x 256 | 2.19 |
| Image Generation | FFHQ 512 x 512 | 2.41 |
| Image Generation | ImageNet 128x128 | 1.81 |
| Image Generation | ImageNet 256x256 | 2.3 |
| Image Generation | ImageNet 32x32 | 1.1 |
| Image Generation | ImageNet 512x512 | 2.4 |
| Image Generation | ImageNet 64x64 | 1.51 |
| Image Generation | Pokemon 1024x1024 | 25.47 |
| Image Generation | Pokemon 256x256 | 23.97 |
| Tasks | Business Use Cases | Examples |
| Image Synthesis | Marketing and advertising | Generate high-quality images of products and services for marketing campaigns. |
| Entertainment and media | Create realistic images of characters and scenes for movies, TV shows, and video games. | |
| Architecture and design | Generate 3D models and architectural visualizations for design and construction projects. | |
| Human face synthesis | Fashion and beauty | Create realistic images of models wearing clothing and accessories for fashion campaigns. |
| Entertainment and media | Generate lifelike images of characters for movies, TV shows, and video games. | |
| Law enforcement and security | Generate images of suspects based on eyewitness descriptions or composite sketches. |
Benchmark Results
Benchmarking is an important process to evaluate the performance of any language model, including StyleGAN-XL. The key results are;
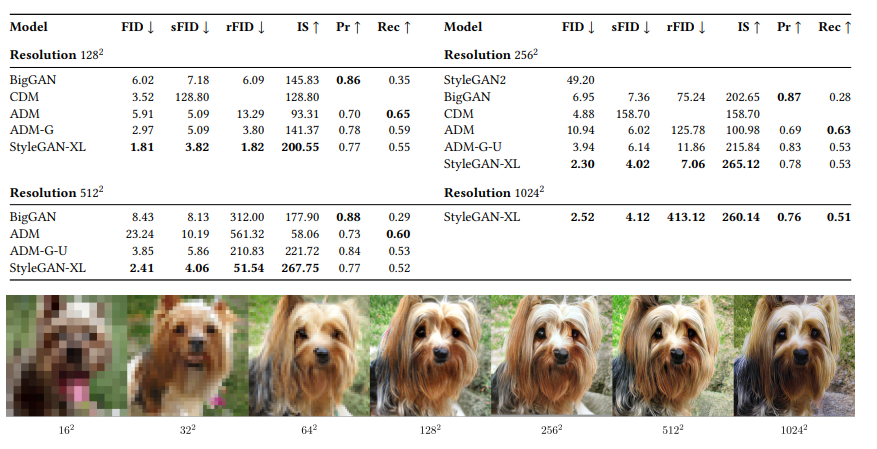
StyleGAN-XL Models
Table - Image Synthesis on ImageNet. Empty cells indicate that the model was unavailable, and the respective metric was not evaluated in the original work.
Figure - Samples at Different Resolutions Using the Same w. The samples are generated by the models obtained during progressive growing. We up a sample of all images to 1024*1024 using nearest-neighbor interpolation for visualization. Zooming in is recommended.
Other LLMs

PFGM++
PFGM++ is a family of physics-inspired generative models that embeds trajectories for N dimensional data in N+D dimensional space using a simple scalar norm of additional variables.
Read More

MDT-XL2
MDT proposes a mask latent modeling scheme for transformer-based DPMs to improve contextual and relation learning among semantics in an image.
Read More

Stable Diffusion
An image synthesis model called Stable Diffusion produces high-quality results without the computational requirements of autoregressive transformers.
Read More