



InstructEval Models Explained,
Flan-UL2
Flan-UL2 is an encoder-decoder Transformer model pre-trained on a massive dataset of text and code. Flan-UL2 has many notable improvements over the original UL2 model. First, it has a larger receptive field of 2048, which makes it more suitable for few-shot in-context learning. Second, it does not require mode switch tokens, which makes it easier to use. Finally, it has been fine-tuned using the Flan prompt tuning and dataset collection, further improving its performance. Flan-UL2 excels across various tasks, encompassing question answering, text summarization, and natural language inference.
Model Details100+ Technical Experts

50 Custom AI projects
4.8 Minimum Rating
An Overview of Flan-UL2
Flan-UL2, an advanced large language model (LLM) created by Google AI. It has demonstrated exceptional performance on a range of NLP benchmarks in June 2023. These comprehensive evaluations encompass tasks such as question-answering, summarization, and natural language inference. Flan-UL2 achieved state-of-the-art results across prominent benchmarks, including GLUE, SQuAD, and RACE.

It was trained on a dataset of text and code containing 1.56TB of text and 600GB of code.
100 billion parameters
Flan-UL2 has a base parameter count of 20 billion and an upper parameter count of 100 billion. This is more than the number of parameters in GPT-3, the previous state-of-the-art LLM.
Flan-UL2 uses 20% less memory than GPT-3 because it is built on a more efficient architecture.
Efficient and scalable
It is based on the Flan architecture, a new LLM architecture built to be more efficient and scalable. This architecture allows Flan-UL2 to run faster using less memory than other LLMs of the same size.
Flan-UL2 can be used to train other LLMs, which can further improve their performance.
Community-driven model
The open-source nature of Flan-UL2 makes it easy to extend the model with new features or capabilities. This allows users to customize the model to meet their specific needs.
Blockchain Success Starts here
Model Details
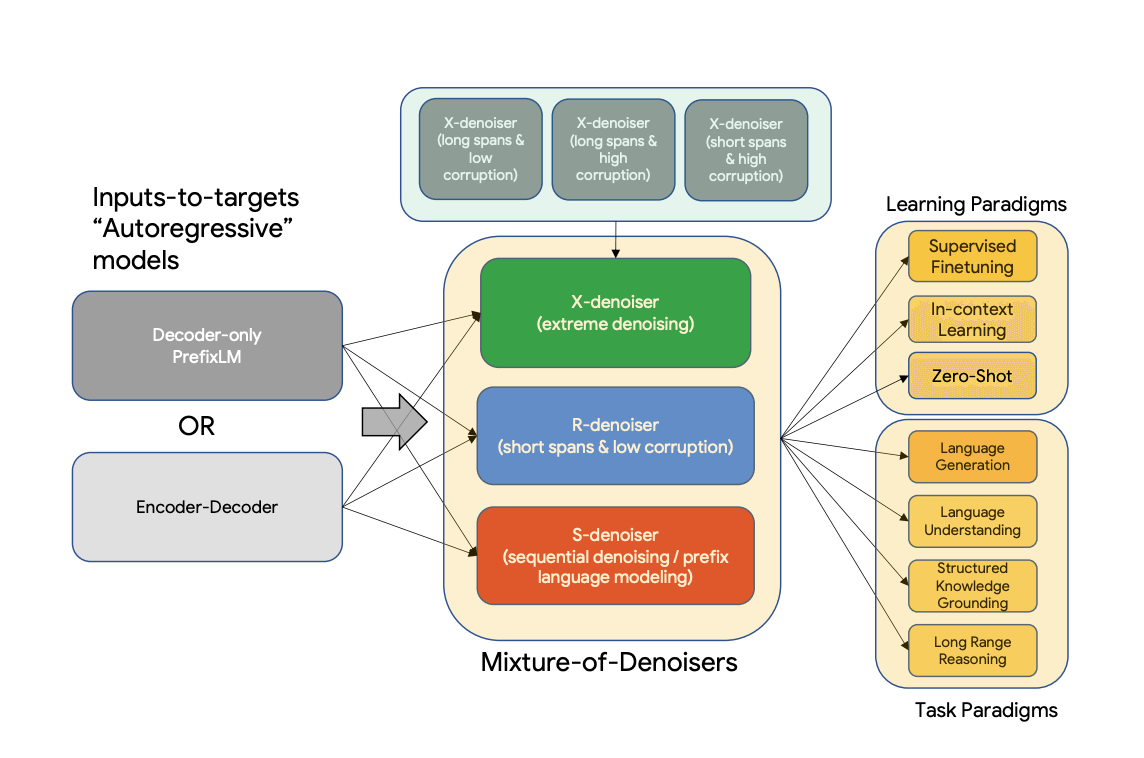
Flan-UL2 was developed by a team of researchers at Google AI, led by Yi Tay. The team developed Flan-UL2 to address the challenges of training large language models (LLMs) on various datasets. Flan-UL2 uses a new pre-training objective called Mixture-of-Denoisers (MoD), which blends the functionalities of diverse pre-training paradigms. In addition, this allows Flan-UL2 to be trained on various datasets while maintaining high performance. Flan-UL2 was trained on a dataset of C4, which is a collection of academic datasets phrased as instructions. So, Flan-UL2 is well-suited for tasks requiring understanding and following instructions, such as machine translation, question answering, and summarization. Flan-UL2 is effective in various natural language processing (NLP) tasks. For example, on the GLUE benchmark, Flan-UL2 achieved an accuracy of 88.5%, comparable to GPT-3. Flan-UL2 has also been effective on tasks requiring few-shot learning, such as code completion and text summarization. Overall, Flan-UL2 is a powerful LLM with several advantages over GPT-3. It is more efficient, more accessible, and just as effective on a variety of NLP tasks. Flan-UL2 is a good choice for applications where resource constraints are a concern but high performance is still required.

Training Details
Training Data
Flan-UL2 is a state-of-the-art, advanced language model meticulously trained on an extensive dataset containing an impressive 560 billion words, encompassing a diverse range of text and code. This vast training corpus empowers the model to acquire a comprehensive understanding of various linguistic intricacies, enabling it to generate text that is not only informative but also captivating.


Training Infrastructure
Flan-UL2, a powerful language model, was trained on an extensive dataset of text and code. Its training utilized a cluster of Google Cloud TPU v4 Pods, the C4 corpus, and the efficient and scalable Megatron-Turing NLG (MT-NLG) framework. The TPU v4 Pods delivered up to 180 petaflops of floating-point performance, essential for training Flan-UL2 on the colossal C4 corpus containing approximately 560 billion words.
Training Objective
Flan-UL2 underwent training using a mixture-of-denoisers (MoD) pre-training objective, which incorporates multiple tasks such as masked language modeling, next-sentence prediction, and code summarization. The MoD objective enhances Flan-UL2's ability to learn diverse linguistic features, enabling high performance across various tasks.
Training Observation
The model underwent extensive training on a massive dataset of 1 trillion tokens, surpassing the scale of previous language models. It employed a novel mixture-of-denoisers objective, enabling it to excel in a wide array of tasks. The model underwent prolonged training, resulting in its impressive performance across different applications. Notably, its efficiency in learning new tasks was attributed to the extensive dataset it was trained on.
| Model | Parameters | Architecture | Initialization | Task |
| Flan-UL2-Base | 20 billion | T5 | Flan | Natural language inference, question answering, summarization, translation, code generation, etc. |
| Flan-UL2-Medium | 40 billion | T5 | Flan | Natural language inference, question answering, summarization, translation, code generation, etc. |
| Flan-UL2-Large | 100 billion | T5 | Flan | Natural language inference, question answering, summarization, translation, code generation, etc. |
Other InstructEval Models

Falcon 7B Instruct
Falcon-7B-Instruct is a 7B parameter causal decoder-only model built by TII based on Falcon-7B and finetuned on a mixture of chat/instruct datasets.
Read More

Alpaca LoRA
Alpaca LoRA is a 65B parameter LLM that has undergone quantization to 4 bits, resulting in a smaller and more efficient model compared to other LLMs.
Read More
OPT-IML
OPT-IML is a collection of instruction-tuned models based on the OPT transformer trained on around 2000 NLP tasks from the OPT-IML Bench.
Read More