



InstructEval Models Explained,
OPT-IML
OPT-IML, a suite of instruction-tuned models derived from the open-source, decoder-only, pre-trained transformers of the OPT family, has undergone training on a comprehensive collection of ~2000 NLP tasks obtained from the acclaimed OPT-IML Bench, comprising 8 NLP benchmarks. This powerful model has extensive applicability in diverse business contexts, including chatbot creation, personalized marketing message generation, customer feedback aggregation, fraud risk assessment, content moderation, disaster relief support, and fraud pattern detection.
Model Details100+ Technical Experts

50 Custom AI projects
4.8 Minimum Rating
An Overview of OPT-IML
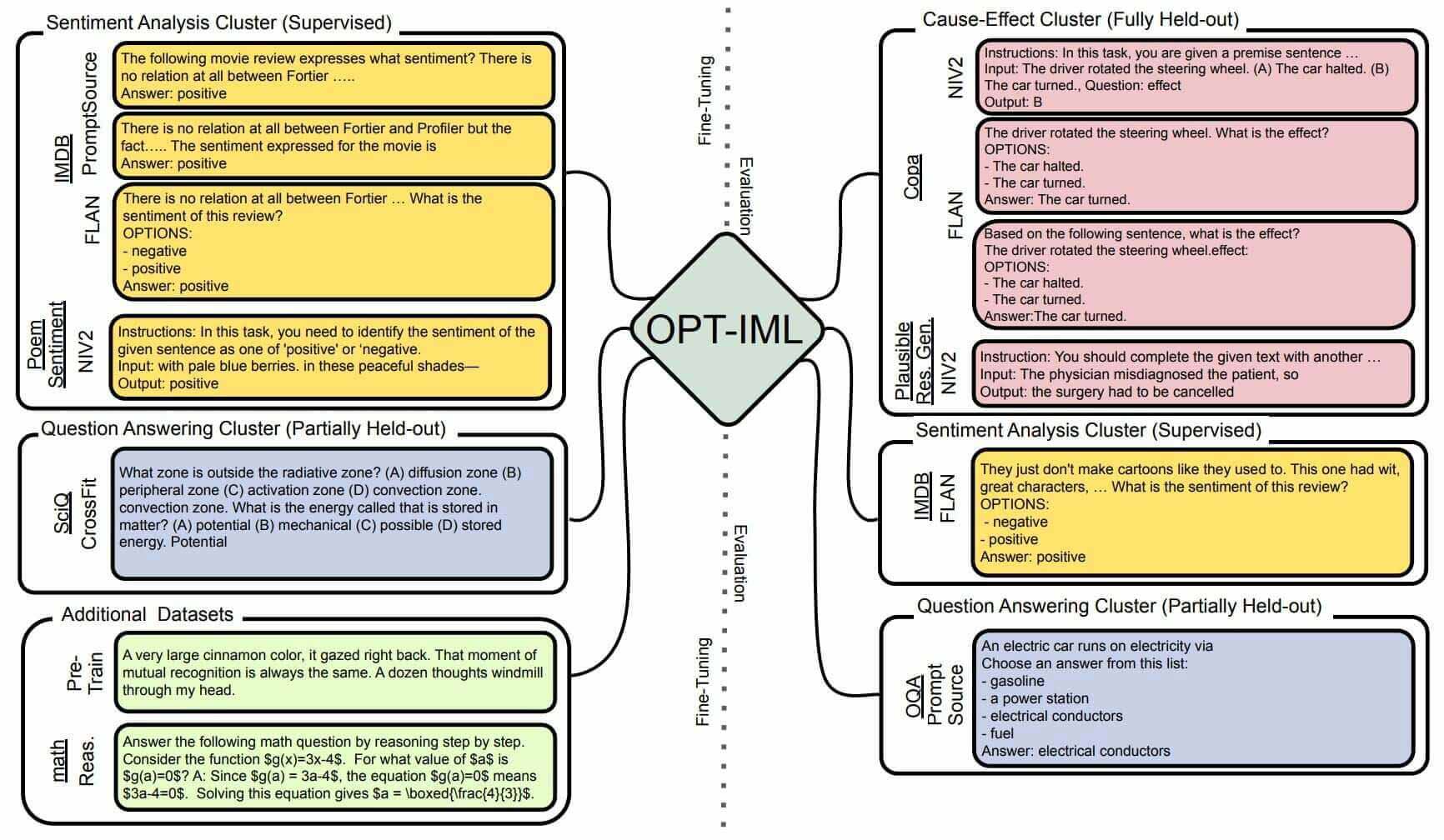
OPT-IML, which stands for OPT + Instruction Meta-Learning, was developed by researchers at Meta AI (formerly Facebook AI). As a substantial benchmark for Instruction Meta-Learning (IML), OPT-IML encompasses a collection of 2000 NLP tasks derived from 8 existing benchmarks, organized into distinct task categories. This comprehensive benchmark evaluates model generalization across three dimensions: tasks from entirely held-out categories, held-out tasks from familiar categories, and held-out instances from familiar tasks. The creation of the OPT-IML benchmark addresses the limitations observed in prior IML research, which primarily focused on modest benchmarks consisting of a few dozen tasks. By scaling both the model and benchmark sizes, OPT-IML enables researchers to explore the impact of instruction-tuning decisions on downstream task performance.

It achieves 93.2% accuracy on noisy held-out tasks from seen categories.
Robustness
OPT-IML's training on a vast and diverse dataset of text and code enhances its robustness, enabling it to easily handle data noise and errors while effectively adapting to unforeseen input and real-world challenges.
OPT-IML is much better at information retrieval tasks compared to GPT-3.
Transferability
OPT-IML exhibits excellent transferability to new tasks, requiring minimal or no additional training. Exposure to diverse tasks during training enables the model to generalize adeptly to novel problem domains.
The model can be trained on datasets 100 times larger than those used for training GPT-3.
Scalability
OPT-IML is highly scalable, allowing for its seamless application to larger models and datasets. This scalability empowers the model to tackle increasingly complex problem domains and leverage extensive data resources for enhanced learning capabilities.
Blockchain Success Starts here
Model Details
OPT-IML, a powerful language model developed by Meta AI, boasts a substantial parameter count of 30 billion. Its extensive capabilities encompass tasks such as question answering, summarization, natural language inference, code generation, and translation. Notably, OPT-IML can learn from instructions, enabling it to comprehend and execute task-specific instructions effectively. In addition to its proficiency in following instructions, OPT-IML has demonstrated remarkable generalization capabilities across new tasks. It showcases enhanced robustness against noise and adversarial examples compared to other large language models (LLMs). The training process of OPT-IML was conducted on a more efficient computing infrastructure, resulting in a significantly reduced carbon footprint of merely 1/7th that of GPT-3. This distinctive characteristic positions OPT-IML as a more environmentally sustainable choice for training large-scale language models.

Training Details
Training Data
The training process for the OPT-IML model involved a curated collection of 2000 NLP tasks sourced from 8 existing benchmarks. These tasks were thoughtfully organized into ten distinct categories, encompassing commonsense, dialogue, instructions, machine translation, natural language inference, question answering, text summarization, text generation, and zero-shot learning. Various sources were utilized to ensure the training data's quality and reliability, including web text, code, and datasets. The model was subsequently trained on the refined dataset using supervised learning techniques.


Training Procedure
During training, emphasis was placed on ensuring the diversity and representativeness of the data, aligning closely with practical scenarios encountered by the OPT-IML model. Tokenization employed GPT2 byte-level Byte Pair Encoding (BPE) with a vocabulary size of 50,272, tailored for Unicode characters. Sequences of 2048 consecutive tokens were formed. Fine-tuning occurred on 64 40GB A100 GPUs, with approximately 2 billion tokens processed, representing just 0.6% of OPT's pre-training budget. OPT-IML offers two versions: OPT-IML trained on 1500 tasks, with some held out for downstream evaluation, and OPT-IML-Max trained on all ~2000 tasks.
Other InstructEval Models

Falcon 7B Instruct
Falcon-7B-Instruct is a 7B parameter causal decoder-only model built by TII based on Falcon-7B and finetuned on a mixture of chat/instruct datasets.
Read More

Alpaca LoRA
Alpaca LoRA is a 65B parameter LLM that has undergone quantization to 4 bits, resulting in a smaller and more efficient model compared to other LLMs.
Read More

StableVicuna
StableVicuna-13B-HF represents an LLM model that has undergone meticulous fine-tuning through reinforcement learning from human feedback (RLHF).
Read More