




T2I Models Explained,
LSGM
The Latent Score-based Generative Model (LSGM) is a novel approach that trains SGMs in a latent space, resulting in more expressive generative models and faster sampling. LSGM introduces a new score-matching objective and proposes a novel parameterization of the score function.
Model Card100+ Technical Experts

50 Custom AI projects
4.8 Minimum Rating
An Overview of LSGM
LSGM introduces a new score-matching objective and proposes a novel parameterization of the score function.

LSGM achieves a FID score of 2.10 on CIFAR-10, which is currently the best results.
2.10 on CIFAR-10
LSGM sets a new record FID score of 2.10 on CIFAR-10, beating all previous generative results.
LSGM utilizes the PyTorch deep learning framework, which is designed to be flexible.
Uses Python 3.8
The LSGM model uses Python 3.8; the source code can be found in the LSGM repository on GitHub.
LSGM attains the best likelihood results on the binarized OMNIGLOT dataset.
SOTA Results
The LSGM model has been able to achieve the highest possible likelihood scores on the binarized OMNIGLOT dataset.
Blockchain Success Starts here
About Model
The Latent Score-based Generative Model (LSGM) is a novel approach that trains SGMs in a latent space, resulting in more expressive generative models and faster sampling. LSGM introduces a new score-matching objective and proposes a novel parameterization of the score function. It obtains a state-of-the-art FID score on CIFAR-10 and achieves state-of-the-art likelihood on the binarized OMNIGLOT dataset. On CelebA-HQ-256, LSGM is on a par with previous SGMs in sample quality while outperforming them in sampling time.

Training Details
Training data
The authors used three datasets to train their model: CIFAR-10, CelebA-HQ, and Omniglot.


Training dataset size
They used 50,000 CIFAR-10 images, 30,000 CelebA-HQ images, and the standard Omniglot dataset of 1,623 characters with 20 instances each.
Training Procedure
The authors used a two-stage training approach for their generative model, first training a VAE and then fine-tuning a score-based model using the VAE's latent space.
Training time and resources
The authors reported the training time for CIFAR-10 on a single NVIDIA V100 GPU to be 3 days and 9 hours.
| Task | Dataset | Score |
| Image Generation | CelebA HQ 256x256 | 7.22 |
| Image Generation (balanced) | CIFAR-10 | 2.17 |
| Image Generation (NLL) | CIFAR-10 | 6.89 |
| Image Generation (FID) | CIFAR-10 | 2.10 |
| Tasks | Business Use Cases | Examples |
| Image Generation | Generating images for advertising, product design, and media | Generating realistic images of furniture, vehicles, landscapes, and other objects |
| Digit Image Generation | Creating datasets for digit recognition algorithms and research | Generating synthetic datasets for digit recognition, generating images for educational purposes |
| Face Image Generation | Generating realistic images of human faces for social media | Generating images of human faces for advertising, product design, or generating realistic 3D models |
| High-Quality Face Image Generation | Generating high-quality images of human faces for video games | Generating images of realistic characters for use in video games and other media productions |
| Handwritten Character Image Generation | Creating datasets for character recognition algorithms and fonts | Generating synthetic datasets for character recognition, creating new fonts, or generating characters for education purposes |
Benchmark Results
Benchmarking is an important process to evaluate the performance of any language model, including LSGM. The key results are;
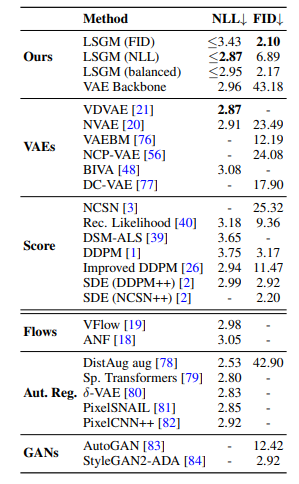
Generative performance on CIFAR-10
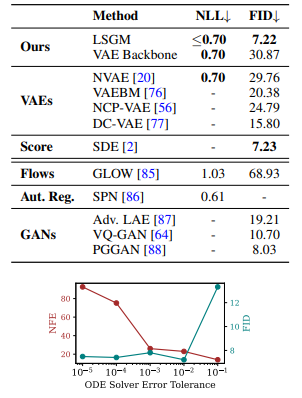
Generative results on CelebA-HQ-256.
Other LLMs

PFGM++
PFGM++ is a family of physics-inspired generative models that embeds trajectories for N dimensional data in N+D dimensional space using a simple scalar norm of additional variables.
Read More

MDT-XL2
MDT proposes a mask latent modeling scheme for transformer-based DPMs to improve contextual and relation learning among semantics in an image.
Read More

Stable Diffusion
An image synthesis model called Stable Diffusion produces high-quality results without the computational requirements of autoregressive transformers.
Read More