



T2I Models Explained,
MDT-XL2
MDT proposes a mask latent modeling scheme for transformer-based DPMs to improve contextual and relation learning among semantics in an image. It operates the diffusion process in the latent space and designs an asymmetric masking diffusion transformer (AMDT) to predict masked tokens.
Model Card100+ Technical Experts

50 Custom AI projects
4.8 Minimum Rating
An Overview of MDT-XL2
MDT proposes a mask latent modeling scheme for transformer-based DPMs to improve contextual and relation learning among semantics in an image. It operates the diffusion process in the latent space and designs an asymmetric masking diffusion transformer (AMDT) to predict masked tokens.

Masked Diffusion Transformer has 3X faster learning speed
3X faster
The MDT model has a learning speed that is three times faster than the previous state-of-the-art DiT model.
Mask latent modeling scheme to enhance the DPMs’ ability
Enhance DPM
Authors employed mask latent modeling to enhance DPMs' contextual relation learning among object semantic parts in images.
The ImageNet dataset is used for training
1.28 Million
The training process utilized the ImageNet dataset, which contains 1.28 million images.
Blockchain Success Starts here
About Model
MDT proposes a mask latent modeling scheme for transformer-based DPMs to improve contextual and relation learning among semantics in an image. It operates the diffusion process in the latent space and designs an asymmetric masking diffusion transformer (AMDT) to predict masked tokens. MDT can reconstruct the full image from its incomplete input and learns the associated relations among semantics in an image. It achieves superior performance on the image synthesis task with a new SoTA on class-conditional image synthesis on the ImageNet dataset. It has about 3x faster learning progress during training than the previous SoTA DPMs.

Training Details
Training data
The authors used the standard ImageNet dataset containing 1.28 million images from 1000 classes.


Training dataset size
The ImageNet dataset used for training consists of 1.28 million images.
Training Procedure
MDT model trained like DiT model with Adam optimizer, lr=1e-4, batch size=32, 150k steps, and lr decreased by 10 at 100k and 125k steps.
Training time and resources
The authors trained the MDT model on 8 NVIDIA Tesla V100 GPUs for 5 days.
| Task | Dataset | Score |
| Image Generation, (MDT 2500k×256) | ImageNet 256x256 | 7.41 |
| Image Generation, (MDT 3500k×256) | ImageNet 256x257 | 6.46 |
| Image Generation, (MDT 6500k×256) | ImageNet 256x258 | 6.23 |
| Image Generation, (MDT-G 2500k×256) | ImageNet 256x259 | 2.15 |
| Image Generation, (MDT-G 3500k×256) | ImageNet 256x260 | 2.02 |
| Image Generation, (MDT-G 6500k×256) | ImageNet 256x261 | 1.79 |
| Tasks | Business Use Cases | Examples |
| Image Synthesis | Design, Advertising, E-commerce | Generating realistic images for product catalogs, digital marketing campaigns, and website design. Examples include generating product images, creating visual content for social media campaigns, and creating realistic architectural visualizations. |
| Bedroom Synthesis | Interior Design, Real Estate | Creating photo-realistic images of bedrooms to help customers visualize spaces in a home, for interior design and real estate industries. Examples include generating realistic images for property listings, interior design mockups, and virtual tours. |
| Face Synthesis | Entertainment, Gaming, Social Media | Creating high-quality synthetic faces for video games, movies, TV shows, and social media platforms. Examples include creating realistic avatars for video games, generating deepfakes for social media, and enhancing visual effects in movies and TV shows. |
Benchmark Results
Benchmarking is an important process to evaluate the performance of any language model, including MDT-XL2. The key results are;
MDT-XL2 models Benchmark Results
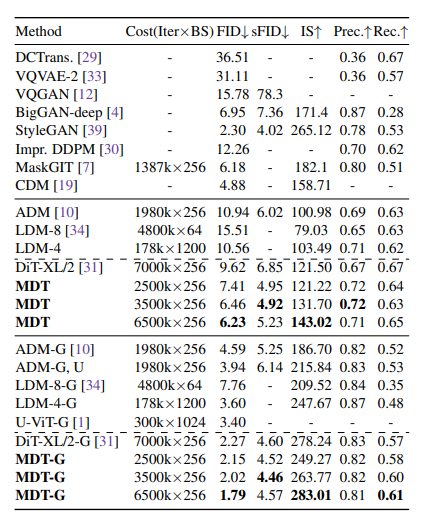
Table 1. Comparison with existing methods on class-conditional image generation with the ImageNet 256×256 dataset. -G denotes the results with classifier-free guidance. Results of MDT-XL/2 model are given for comparison. Compared results are obtained from their papers.
MDT-XL2 models Benchmark Results
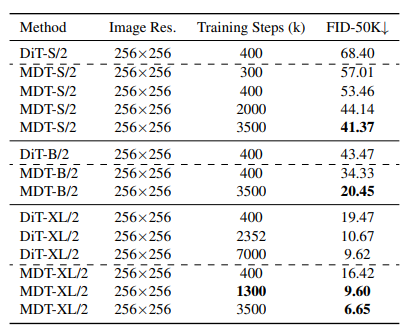
Table 2. Comparison between DiT and MDT under different model sizes and training steps on ImageNet 256×256. DiT results are obtained from DiT reported results.
Other LLMs

PFGM++
PFGM++ is a family of physics-inspired generative models that embeds trajectories for N dimensional data in N+D dimensional space using a simple scalar norm of additional variables.
Read More

MDT-XL2
MDT proposes a mask latent modeling scheme for transformer-based DPMs to improve contextual and relation learning among semantics in an image.
Read More

Stable Diffusion
An image synthesis model called Stable Diffusion produces high-quality results without the computational requirements of autoregressive transformers.
Read More