

August 3rd, 2023: Today marks an exciting day for Accubtis Technologies and the Bud Ecosystem as they proudly announce the open-sourcing of GenZ MM-VT-7B, a powerful, multimodal large language model (LLM). With 7 billion parameters, the model exhibits unique capabilities to comprehend and process both text and image inputs.
As we navigate an increasingly data-driven world, the ability to interpret and learn from diverse data types is paramount. This is the key strength of GenZ MM-VT-7B. It represents a significant leap over traditional text-only models, capable of comprehending complex content, extracting nuanced meanings, and responding effectively by processing text and images together. The integration of these modalities fosters a holistic understanding of data, heralding unprecedented potential for various applications.
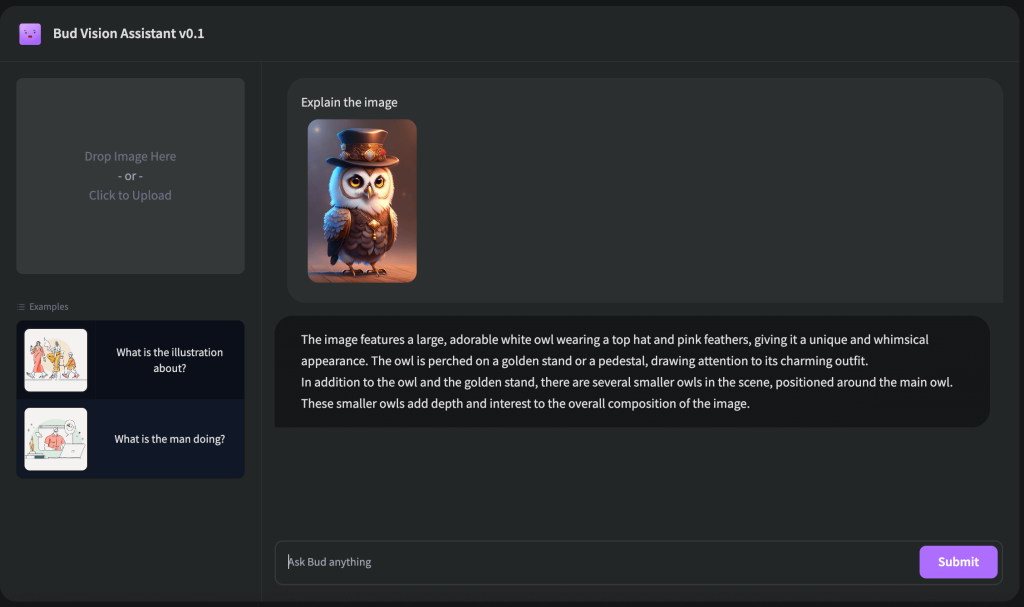



The novelty of GenZ MM-VT-7B’s architecture lies in its 7 billion parameters, enabling it to comprehend and generate human-like text while simultaneously interpreting visual inputs. This innovative feature unlocks a vast array of potential use cases.
We are excited and equally stunned to observe that this relatively compact Multi-Modal Language Learning Model manifested emergent phenomena such as Optical Character Recognition (OCR) comprehension, spatial reasoning, entity relationship recognition, and bounding box-based entity understanding. Intriguingly, these capabilities surfaced without the model being expressly trained to acquire these skills.
Perhaps the most transformative characteristic of this model is its adeptness at connecting the dots between textual and visual data. In contrast to traditional models that only handle a single modality, GenZ MM-VT-7B transcends these limitations, processing and linking diverse data types for an enriched, holistic comprehension of the information.
The enriched context stemming from this dual-modality approach is profound. The model can discern deeper meanings from texts referencing visuals and draw correlations between textual descriptions and their corresponding images. This confluence of text and image understanding has far-reaching implications – enhancing machine-generated content, refining search result relevancy, or improving the accuracy of automated data analyses.
The multimodal nature of GenZ MM-VT-7B also ushers in a wealth of unexplored use cases. For example, its ability to blend text and image comprehension could revolutionize the educational sector by providing comprehensive tutoring assistance and explaining complex concepts through a blend of text and images. In digital marketing, the model could perform thorough analyses of online consumer behavior, making sense of the text in social media posts or reviews while interpreting the accompanying visual content.
Large Language Models like GenZ MM-VT-7B are seen as harbingers of a new trajectory in human evolution. They’re not just tools to enhance our existing abilities; they symbolize a new era akin to the advent of the industrial revolution or the digital age. LLMs democratize skills, making it easier for anyone to become an artist, writer, or programmer. They empower people to express their creativity, craft compelling narratives, or devise software solutions, fostering an inclusive culture of talent and skill.
Nevertheless, the broad accessibility of LLMs is still a hurdle. Large corporations and research institutions currently bear the infrastructural costs associated with LLMs, making them inaccessible to many due to the prohibitive expense. Through GenZ, we aim to tackle this issue head-on. Our mission is to build an open-source foundational model that not only houses the knowledge and reasoning capabilities of GPT4 but also prioritizes privacy and can be hosted even on a mobile device. We believe this revolutionary technology should be accessible to all – every developer, entrepreneur, and business should have the opportunity to experiment, innovate, and build groundbreaking solutions with these models. The power of LLMs should not be restricted to a privileged few but harnessed for the collective progress of society. GenZ MM-VT-7B is a step closer to this mission.
We invite all data scientists, machine learning engineers, researchers, and those passionate about AI to explore and build upon GenZ MM-VT-7B. Driven by our belief in the power of open-source software, we hope this initiative will spark a wave of collaboration and innovation. At Accubtis Technologies and Bud Ecosystem, we are thrilled to contribute to the advancement of AI technology and can’t wait to see the myriad ways this new multimodal LLM will be employed. We eagerly anticipate working alongside the global AI community to shape the future of machine learning.
Drop us a word if you want to know more about the model or need help adopting LLMs in your enterprise.
Intended Use
When we created GenZ MM-VT-7B, we had a clear vision of how it could be used to push the boundaries of what’s possible with multimodal large language models. We also understand the importance of using such models responsibly. Here’s a brief overview of the intended and out-of-scope uses for GenZ MM-VT-7B.
Out-of-Scope Use
While GenZ 13B is versatile, there are certain uses that are out of scope:
Remember, GenZ MM-VT-7B, like any large language model, is trained on a large-scale corpora representative of the web, and therefore, may carry the stereotypes and biases commonly encountered online.
Recommendations
We recommend users of GenZ MM-VT-7B to consider fine-tuning it for the specific set of tasks of interest. Appropriate precautions and guardrails should be taken for any production use. Using GenZ MM-VT-7B responsibly is key to unlocking its full potential while maintaining a safe and respectful environment.
