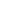
Leaders
As of March 28, the top three leaders in the open-source program synthesis models are CodeGeeX, InCoder, and CodeGen. Based on our scoring methodology, these models scored 79, 69, and 64 points, respectively. The scoring methodology is explained below. The current leader is CodeGeeX, a large-scale multilingual code generation model with 13 billion parameters pre-trained on a large code corpus of over 20 programming languages. The Model is published by Knowledge Engineering Group (KEG) & Data Mining at Tsinghua University. As of June 22, 2022, CodeGeeX has been trained on more than 850 billion tokens on a cluster of 1,536 Ascend 910 AI Processors. CodeGeeX is available in the VS Code extension marketplace for free. It supports code completion, explanation, summarization, and more, which empowers users with a better coding experience.
| Rank | Model | Size | Architecture | Organization | Adoption Rating  Calculated based on the number of forks and stars on the official model repo. Calculated based on the number of forks and stars on the official model repo. | Capability Rating Calculated based on the number of tasks and downstream tasks of the model. | Score A weighted average of the adoption and capability score of the model. |
| #1 | Codegeex | 13B | Transformer | Tsinghua University | 92 | 67 | 79 |
| #2 | Incoder | 6.7B | Transformer | Meta AI | 96 | 43 | 69 |
| #3 | Codegen | 16B | Transformer | Salesforce | 79 | 49 | 64 |
| #4 | CodeT5 | 220M | Transformer | Salesforce | 31 | 60 | 45 |
| #5 | CodeRL | 770M | Transformer | Salesforce | 47 | 40 | 43 |
| #6 | Codebert | 125M | Transformer | Microsoft | 23 | 56 | 39 |
| #7 | Polycoder | 2.7B | Transformer | Carnegie Mellon University | 42 | 11 | 26 |
| - | Santacoder | 1.1B | Transformer | Bigcode | - | 45 | - |
Need help with Generative AI?
If you have any questions or need a helping hand, don't hesitate to reach out.

Let’s Get Started
The first step towards greatness begins now, let's embark on this journey.
Help us Help you.
Share more information with us, and we'll send relevant information that cater to your unique needs.
Final Touch
Kindly share some details about your company to help us identify the best-suited person to contact you.
Contact Details
Generative AI Adoption Framework
This whitepaper will explore generative AI and identify business growth opportunities it offers. We aim to provide business owners with a comprehensive guide to using AI to unlock new opportunities and achieve sustainable growth. We will explore how generative AI can be used to analyze data and identify patterns, as well as how it can be used to generate new ideas and solutions.
Free Download