




Code LLMs Explained,
CodeGeeX
CodeGeeX, a large-scale multilingual code generation model with 13 billion parameters pre-trained on a large code corpus of over 20 programming languages. The Model is published by Knowledge Engineering Group (KEG) & Data Mining at Tsinghua University. As of June 22, 2022, CodeGeeX has been trained on more than 850 billion tokens on a cluster of 1,536 Ascend 910 AI Processors.
Model DetailsTechnical Experts

50 Custom AI projects
4.8 Minimum Rating
An Overview of CodeGeeX
CodeGeeX is a large-scale multilingual code generation model that boasts 13 billion parameters and is trained on an extensive code corpus encompassing more than 10+ programming languages.

Extensive training on a massive dataset
850B tokens
CodeGeeX, the multilingual code generation model, has undergone extensive training on a massive dataset consisting of over 850 billion tokens.
Variety of programming languages
10+ languages
CodeGeeX is a versatile code generation model that supports 10+ popular programming languages, such as Python, Java, C++, C, JavaScript, and Go.
Available in popular IDEs as an extension or plugin
Extensions
CodeGeeX offers Customizable Programming Assistant in VS Code and JetBrains IDEs as an extension/plugin. It empowers users with a better coding experience.
Blockchain Success Starts here
About Model
CodeGeeX is a cutting-edge code generation model with a capacity of 13 billion parameters, designed to support multiple programming languages. The model has been pre-trained on an extensive code corpus of more than 20 popular programming languages to enable it to generate high-quality code in diverse contexts. It performs well for generating executable programs in several mainstream programming languages, including Python, C++, Java, JavaScript, Go, etc. It also supports the translation of code snippets between different languages. With one click, CodeGeeX can transform a program into any expected language with high accuracy. All codes and model weights are publicly available for research purposes. It is free in the VS Code extension marketplace, and It supports code completion, explanation, summarization, and more.

Training Details
Training data
The model's training data is divided into two main sections. The first section is derived from publicly available datasets of code, namely The Pile and CodeParrot. The second section comprises code directly scraped from public GitHub repositories. This section contains code samples from popular programming languages such as Python, Java, and C++, among others.


Training Procedure
The training procedure of CodeGeeX involves implementing the model in MindSpore 1.7 and training it on a cluster of 1,536 Ascend 910 AI Processors with 32GB of memory. The model weights are primarily in the FP16 format, except for layer-norm and softmax layers, where FP32 is used for higher precision and stability. The entire model consumes approximately 27GB of memory.
Training dataset size
The Pile is a subset of a larger code corpus that focuses on collecting code from public repositories on GitHub that have more than 100 stars. The authors select code samples from these repositories in 23 popular programming languages. To obtain higher-quality data, the authors narrow down our selection to repositories with at least one star and a size smaller than 10MB.
Training time and resources
CodeGeeX's training process demands substantial computational resources and time. The model is built using MindSpore 1.7 and trained on a cluster of 1,536 Ascend 910 AI Processors, each with 32GB of memory. The entire model requires about 27GB of memory to function properly.
| Task | Dataset | Score |
| pass@100 avg | HumanEval-X | 62 |
| Crosslingual Code Translation (avg of pass@100) | HumanEval-X | 72.5 |
Benchmark Results
Benchmarking is an important process to evaluate the performance of any language model, including CodeGeeX. The key results are;
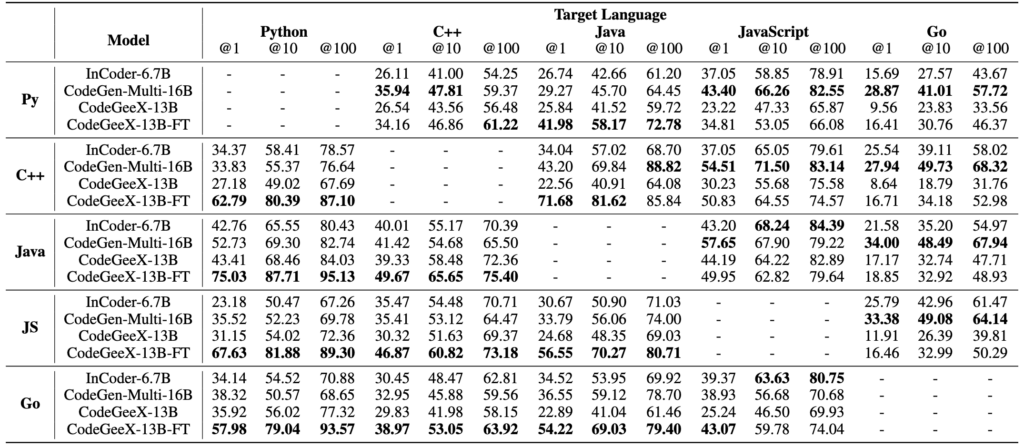
Results on HumanEval-X code translation task. Best language-wise performances are bolded. The results indicate that models have a preference for languages, e.g., CodeGeeX is good at translating other languages to Python and C++, while CodeGen-Multi-16B is better at translating to JavaScript and Go; these could probably be due to the difference in language distribution in the training corpus
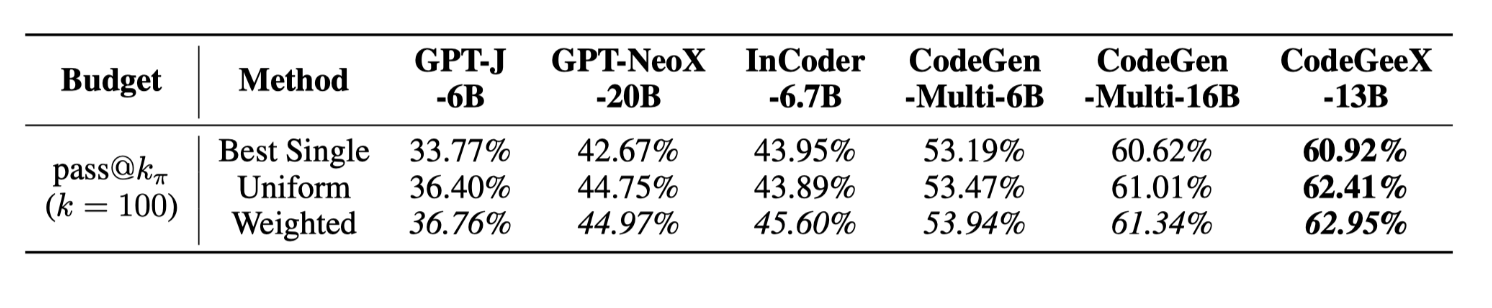
Results for fixed-budget multilingual generation on HumanEval-X. Best model-wise performance on methods are bolded, while best method-wise performance for models are in italic.
Other LLMs

Polycoder
Polycoder is a deep learning model for multilingual natural language processing tasks
Read More

CodeGeex
CodeGeeX, a large-scale multilingual code generation model with 13 billion parameters pre-trained
Read More

CodeRL
CodeRL is a novel framework for program synthesis tasks that combines pretrained language models (LMs)
Read More