




Program Synthesis Model,
CodeRL
CodeRL is a novel framework for program synthesis tasks that combines pretrained language models (LMs) with deep reinforcement learning (RL) techniques to overcome the limitations of existing code generation methods.
Model DetailsTechnical Experts

50 Custom AI projects
4.8 Minimum Rating
An Overview of CodeRL
CodeRL is a novel framework for program synthesis tasks that combines pretrained language models (LMs) with deep reinforcement learning (RL) techniques to overcome the limitations of existing code generation methods.

CodeRL's training process involves an actor network.
Actor-Critic Architecture
CodeRL trains a code-generating AI called an "actor-network" alongside a "critic-network" that evaluates how well the generated code works.
CodeRL introduces a critical sampling strategy
Critical Sampling Strategy
CodeRL uses a sampling technique during testing that incorporates feedback from both unit tests and the critic network
CodeRL achieves new SOTA results
New SOTA Results
CodeRL achieves new SOTA results on two distinct benchmarks - the challenging APPS benchmark and the simpler MBPP benchmark.
Blockchain Success Starts here
About Model
CodeRL is a novel framework for program synthesis tasks that combines pretrained language models (LMs) with deep reinforcement learning (RL) techniques to overcome the limitations of existing code generation methods. Traditional program synthesis methods, which use a standard supervised fine-tuning procedure, often fail to utilize important signals in problem specifications, such as unit tests. As a result, these approaches may struggle to solve complex, unseen coding tasks effectively. To tackle these limitations, CodeRL employs a unique approach that leverages both pretrained LMs and RL. During the training process, the code-generating LM acts as an actor network, while a critic network is introduced to predict the functional correctness of the generated programs. The critic network provides dense feedback signals to the actor, allowing for better learning and adaptation.

Training Details
Training data
The research paper does not provide explicit information about the training data used for CodeRL.


Training dataset size
The research paper does not provide explicit information about the training dataset size used for CodeRL. However, it is worth noting that the pretraining step involves using a large corpus of public Python code and natural language data, typically involving millions or even billions of tokens.
Training procedure
CodeRL has two stages: pretraining and fine-tuning. In pretraining, the model learns Python syntax and natural language understanding. In fine-tuning, the model is trained on a dataset of natural language problem descriptions and Python programs using deep reinforcement learning.
Training time and resources
The research paper does not provide specific details about the training time and resources required for CodeRL. However, training large-scale language models like CodeRL typically involves significant computational resources and time.
| Model | Highlight |
| CodeT5-large | A 770M-CodeT5 model trained with Masked Span Prediction objective on CSN obtained new state-of-the-art results on various CodeXGLUE benchmarks. |
| CodeT5-large-ntp-py | The 770M-CodeT5 model was pre-trained using Masked Span Prediction objective on CSN and GCPY, and then with Next Token Prediction objective on GCPY. |
| CodeT5-finetuned_critic | The model is based on CodeT5-base and is capable of predicting Compile Error, Runtime Error, Failed Tests, and Passed Tests outcomes. |
| CodeT5-finetuned_critic_binary | Similar to the previous model, this one was trained to predict whether unit tests passed or failed. A critic was used to aid in generating procedures during inference. |
| CodeT5-finetuned_CodeRL | A CodeT5 model which was initialized from the prior pretrained CodeT5-large-ntp-py and then finetuned on APPS following our CodeRL training framework. |
| Task | Dataset | Score |
| Pass@1 | APPS | 2.69 |
| Pass@5 | APPS | 6.81 |
| Pass@1000 | APPS | 20.98 |
| 1@k | APPS | 8.48 |
| 5@k | APPS | 12.62 |
| Code-to-Text generation | CodeXGLUE | 19.87 |
| Text-to-Code generation | CodeXGLUE | 45.08 |
| Code-to-Code generation (Java to C#) | CodeXGLUE | 83.56 |
| Code-to-Code generation (C# to Java) | CodeXGLUE | 79.77 |
| Code refine (medium) | CodeXGLUE | 89.22 |
| zero-shot transfer ability | MBPP | 63 |
Benchmark Results
Benchmarking is an important process to evaluate the performance of any language model, including CodeRL. The key results are;
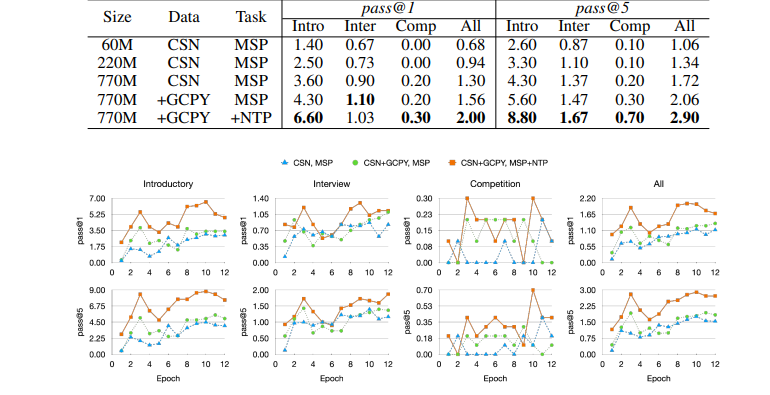
Table: Ablation results of CodeT5 pretrained model variants: We report the results of models pretrained on different configurations by model size, pretraining data, and pretraining task. CSN: CodeSearchNet, GCPY: Github Code Python, MSP: Masked Span Prediction, NTP: Next Token Prediction. For a fair comparison, all models are finetuned only with Lce on APPS.
Figure: Ablation results by finetuning epochs: We report the finetuning progress of CodeT5- 770M models that are pretrained on different configurations by pretraining data and pretraining tasks. CSN: CodeSearchNet, GCPY: Github Code Python, MSP: Masked Span Prediction, NTP: Next Token Prediction. All models are finetuned only with Lce on APPS.
Other LLMs

Polycoder
Polycoder is a deep learning model for multilingual natural language processing tasks
Read More

CodeGeex
CodeGeeX, a large-scale multilingual code generation model with 13 billion parameters pre-trained
Read More

CodeRL
CodeRL is a novel framework for program synthesis tasks that combines pretrained language models (LMs)
Read More