




Code LLMs Explained,
CodeT5
CodeT5, developed by Salesforce Research, is a Transformer model that improves code understanding and generation using developer-assigned identifiers. Their method includes a pre-training task for distinguishing code tokens that are identifiers, as well as a dual-generation task that uses user-written code comments. Experiments show that CodeT5 outperforms previous methods on various understanding and generation tasks and better captures code semantics.
Model DetailsTechnical Experts

50 Custom AI projects
4.8 Minimum Rating
An Overview of CodeT5
CodeT5 leverages the power of large-scale pre-training on code data, combined with fine-tuning on downstream code-related tasks, to improve the accuracy and efficiency of code-related applications.

SOTA results on the 14 sub-tasks in CodeXGLUE.
SOTA results 14 sub-tasks
The research paper on CodeT5 shows that it yields state-of-the-art results on the fourteen sub-tasks in CodeXGLUE.
CodeT5 is a newly developed encoder-decoder model
8.35 million Functions
CodeT5 is a recently developed encoder-decoder model designed for programming languages, and it has been pre-trained on a dataset of 8.35 million functions
CodeT5 achieves over 99% F1 for all PLs for identifier tagging.
Over 99% F1 for all PLs
Researchers also identify the identifier tagging performance and find it achieves over 99% F1 for all PLs, showing that CodeT5 can confidently distinguish identifiers in code.
Blockchain Success Starts here
About Model
CodeT5 is a pre-trained Transformer model designed specifically for code understanding and generation tasks. The model is based on the T5 architecture, which has been widely used for natural language processing tasks. CodeT5 leverages the power of large-scale pre-training on code data, combined with fine-tuning on downstream code-related tasks, to improve the accuracy and efficiency of code-related applications.

Training Details
Training data
CodeSearchNet is used to pre-train CodeT5, consisting of six PLs with unimodal and bimodal data. Two C/CSharp datasets from BigQuery also ensure that all downstream tasks have overlapped PLs with the pre-training data.


Training Procedure
Tokenization is critical to the success of pre-trained language models such as BERT and GPT. Like T5, CodeT5 is trained on a Byte-level BPE tokenizer with a vocabulary size of 32,000. There are also additional special tokens such as [PAD], [CLS], [SEP], [MASK0],..., [MASK99].
Training dataset size
The CODEX dataset comprises over 1.1 million functions with their corresponding natural language descriptions. The dataset is split into a training set (70%), validation set (10%), and test set (20%).
Training Time and Resources
The total training time for CodeT5-small and CodeT5-base is 5 and 12 days, respectively. Code T5 is pre-trained with the denoising objective for 100 epochs and bimodal dual training for another 50 epochs on a cluster of 16 NVIDIA A100 GPUs with 40G memory.
| Model | Parameters | Highlight |
| CodeT5-small | 60 million | Smaller and faster than the original CodeT5 model, making it more efficient and easier to deploy on resource-constrained devices. |
| Dual-gen | Varies | Designed to generate code from both natural language and code inputs, allowing for tasks such as code completion with partial code input. |
| Multi-task | Varies | Can perform multiple code-related tasks simultaneously, allowing for more efficient and effective learning and generalization across tasks. |
| Task | Dataset | Score |
| code summarization | BLEU-4 | 19.77 |
| Code generation | BLEU | 41.48 |
| Code generation | CodeBLEU | 44.1 |
| Code generation | EM | 22.7 |
| Code translation (Java to C#) | BLEU-4 | 84.03 |
| Code translation (C# to Java) | BLEU-4 | 79.87 |
| code refine (medium) | BLEU-4 | 87.64 |
| code defect detection | PLBART | 65.78 |
| code clone detection | PLBART | 97.2 |
Benchmark Results
Benchmarking is an important process to evaluate the performance of any language model, including CodeT5. The key results are;
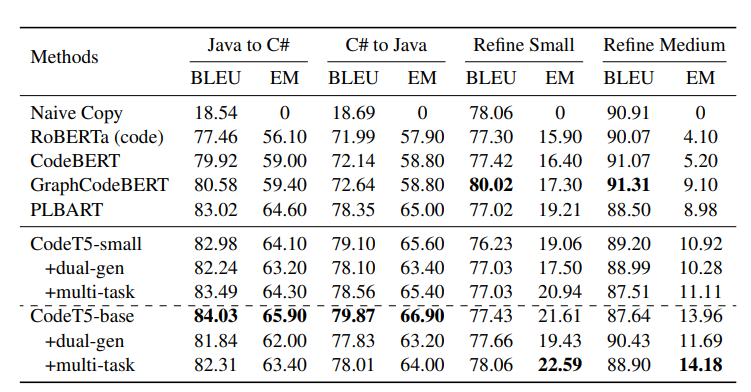
BLEU-4 scores and exact match (EM) accuracies for code translation (Java to C# and C# to Java) and code refinement (small and medium) tasks.
Other LLMs

Polycoder
Polycoder is a deep learning model for multilingual natural language processing tasks
Read More

CodeGeex
CodeGeeX, a large-scale multilingual code generation model with 13 billion parameters pre-trained
Read More

CodeRL
CodeRL is a novel framework for program synthesis tasks that combines pretrained language models (LMs)
Read More