




Code LLMs Explained,
InCoder
InCoder is a large-scale generative code model that can synthesize and edit programs by infilling masked code. After being trained on permissively licensed code, it can infill any region of code, resulting in improved performance on tasks like type inference and variable renaming. Because of the bidirectional context, the model performs well on challenging tasks such as comment generation in zero-shot settings. On program synthesis benchmarks, it performs similarly to left-to-right models.
Model DetailsTechnical Experts

50 Custom AI projects
4.8 Minimum Rating
An Overview of Incoder
InCoder is a generative model for code infilling and synthesis designed to assist developers in writing and completing code by automatically generating missing or required code segments.

InCoder achieves 82.43% accuracy on CodeXGLUE.
82.43% Accuracy
InCoder achieved 82.43% accuracy on the CodeXGLUE benchmark. It is widely used for code-infilling tasks, demonstrating the effectiveness of InCoder's neural language modeling approach.
Trained on a total of 159 GB of code and 28 languages
Trained on 159 GB of code
InCoder is trained on a large dataset with a total of 159 GB of code, 52 GB of it in Python, and 57 GB of content from StackOverflow. And trained in 28 languages, all included in StackOverflow.
Trained on a single NVIDIA GeForce RTX 2080 Ti GPU.
Trained on NVIDIA GeForce
InCoder achieves top performance on code infilling and synthesis tasks with training on a single NVIDIA GeForce RTX 2080 Ti GPU using the PyTorch deep learning framework,
Blockchain Success Starts here
About Model
InCoder is a generative model for code infilling and synthesis designed to assist developers in writing and completing code by automatically generating missing or required code segments. Based on advanced machine learning algorithms and trained on vast source code repositories, InCoder leverages state-of-the-art natural language processing techniques, such as transformer-based models, to comprehend the underlying structure and semantics of programming languages. This enables the model to perform code infilling and synthesis, allowing developers to quickly prototype new ideas, explore alternative implementations, and learn new programming techniques. InCoder's language-agnostic design and integration with popular integrated development environments (IDEs) and code-editing tools provide a seamless experience for developers, enhancing productivity and code quality across different projects and platforms.

Training Details
Training data
The model was trained on public open-source repositories with a permissive, non-copyleft license (Apache 2.0, MIT, BSD-2, or BSD-3) from GitHub and GitLab, as well as StackOverflow. Repositories primarily contained Python and JavaScript but also included code from 28 languages, as well as StackOverflow.


Training Procedure
During training, contiguous token spans are randomly masked in each document. The number of spans is sampled from a Poisson distribution with a mean of one and truncated to [1,256]. The span length is uniformly sampled from the document, and overlapping spans are rejected and resampled.
Training dataset size
After filtering and deduplication, the data corpus contains 159 GB of code, 52 GB of it in Python, and 57 GB of StackOverflow content. While training, the per-GPU batch size was 8, with a maximum token sequence length of 2048.
Training time and resources
INCODER-6.7B was trained on 248 V100 GPUs for 24 days. One epoch on the training data was performed, using each training document exactly once. The per-GPU batch size was 8, with a maximum token sequence length of 2048.
| Model | Parameters |
| incoder-6B | 6.7B |
| incoder-1B | 1B |
| Task | Dataset | Score |
| Single-line infilling (L-R single) | HumanEval | 48.2 |
| Single-line infilling (L-R reranking) | HumanEval | 54.9 |
| Single-line infilling (CM infilling) | HumanEval | 69 |
| Multi-line infilling (L-R single) | HumanEval | 24.9 |
| Multi-line infilling (L-R reranking) | HumanEval | 28.2 |
| Multi-line infilling (CM infilling) | HumanEval | 38.6 |
| Python Docstring generation avg | CodeXGLUE | 17.15 |
| code generation (pass@100) | HumanEval | 47 |
| code generation (pass@100) | MBPP | 19.4 |
| Left-to-right single | HumanEval | 48.2 |
| Left-to-right reranking | HumanEval | 54.9 |
| Infilling | HumanEval | 69 |
Benchmark Results
Benchmarking is an important process to evaluate the performance of any language model, including Incoder. The key results are;
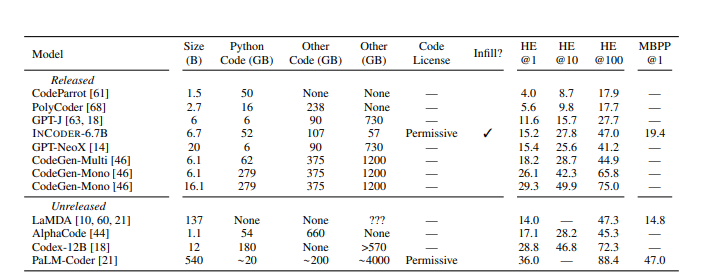
A comparison of our INCODER-6.7B model to published code generation systems using
pass rates @ K candidates sampled on the HumanEval and MBPP benchmarks. All models are
decoder-only transformer models. A “Permissive” code license indicates models trained on only
open-source repositories with non-copyleft licenses. The GPT-J, GPT-NeoX, and CodeGen models
are pre-trained on The Pile [26], which contains a portion of GitHub code without any license filtering,
including 6 GB of Python. Although the LaMDA model does not train on code repositories, its
training corpus includes ∼18 B tokens of code from web documents. The total file size of the LaMDA
corpus was not reported, but it contains 2.8 T tokens total. We estimate the corpus size for PaLM
using the reported size of the code data and the token counts per section of the corpus.
Other LLMs

Polycoder
Polycoder is a deep learning model for multilingual natural language processing tasks
Read More

CodeGeex
CodeGeeX, a large-scale multilingual code generation model with 13 billion parameters pre-trained
Read More

CodeRL
CodeRL is a novel framework for program synthesis tasks that combines pretrained language models (LMs)
Read More