This website stores cookies on your computer. These cookies are used to collect information about how you
interact with our website and allow us to remember you. We use this information in order to improve and
customize your browsing experience and for analytics and metrics about our visitors both on this website and
other media. To find out more about the cookies we use, check our Privacy Policy
We believe, we are striding into the next phase of human evolution where technology negates
the human miseries and we humans can work towards sustaining humanity. We constantly focus
on innovations to make this future closer to us.
White Papers
Generative AI in Banking and Financial Services
Explore this whitepaper on Generative AI in Banking and Financial Services. Discover its potential to transform business and improve billions of lives.
In this whitepaper, we will explore generative AI and identify business growth opportunities it offers. We aim to provide business owners with a comprehensive guide to using AI to unlock new opportunities and achieve sustainable growth. We will explore how generative AI can be used to analyze data and identify patterns, as well as how it can be used to generate new ideas and solutions.
This Whitepaper explores Web3, a decentralized web built on blockchain technology, and its potential benefits for businesses. The benefits of transparency, security, user control, and tokenization are highlighted in the paper. To better understand the technology, it refers to Web2 and Web2.5 as predecessors to Web3. Security, privacy, and regulatory concerns are all acknowledged risks. The paper also emphasizes Web3's potential to transform industries and encourages businesses to stay ahead of the curve and embrace the Internet's future.
Essentials for launching a successful blockchain product
This whitepaper will explore the essentials for launching a successful blockchain product. In the first section, we’ll explore how to choose the right blockchain for developing your DApp. In the second section, we’ll explore the essentials for DApp development, including the best practices, methodologies, common vulnerabilities, audit process, and tools. In the final section, we’ll explore the fundamentals of token economy design for your blockchain project.
Learn on How to develop an Online Education Platform
Here's a step-by-step checklist to get your e-Learning project off the ground. This guide includes technical functionalities, a feature list, and more viable information for your project.
Do you intend to create an NFT marketplace? Do you want to learn how to build an NFT marketplace platform from the ground up? Here's a handy checklist to get you started. This document contains technical specifications, a feature list, and other useful information for your NFT project.
Hey everyone, your tech team from Accubits is back! There’s no denying the power of Generative AI APIs from providers like OpenAI, Anthropic, and Mistral. They’ve democratized access to world-class AI, allowing any developer to integrate incredible intelligence into their applications with zero upfront hardware investment. This accessibility is a double-edged sword. The pay-as-you-go model that makes it so easy to start is the very same mechanism that can lead to jaw-dropping,unexpected bills at the end of the month, making the challenge of Reducing GenAI API Costs a top priority for businesses.
The core of the problem lies in a simple, yet often misunderstood, unit: the token. Every piece of text you send to the model (your prompt) and every word it generates in response costs you money. Inefficient prompts, rambling responses, and poor model selection can inflate your costs by 10x or even 100x without any real improvement in quality. The good news is that you don’t have to choose between a powerful AI feature and a healthy budget. Smart, strategic optimization can dramatically lower your expenses without sacrificing the performance your users love.
This guide is your practical playbook for Reducing GenAI API Costs. We’ll move beyond theory and give you nine actionable tips you can implement today to make your AI features more efficient and sustainable.
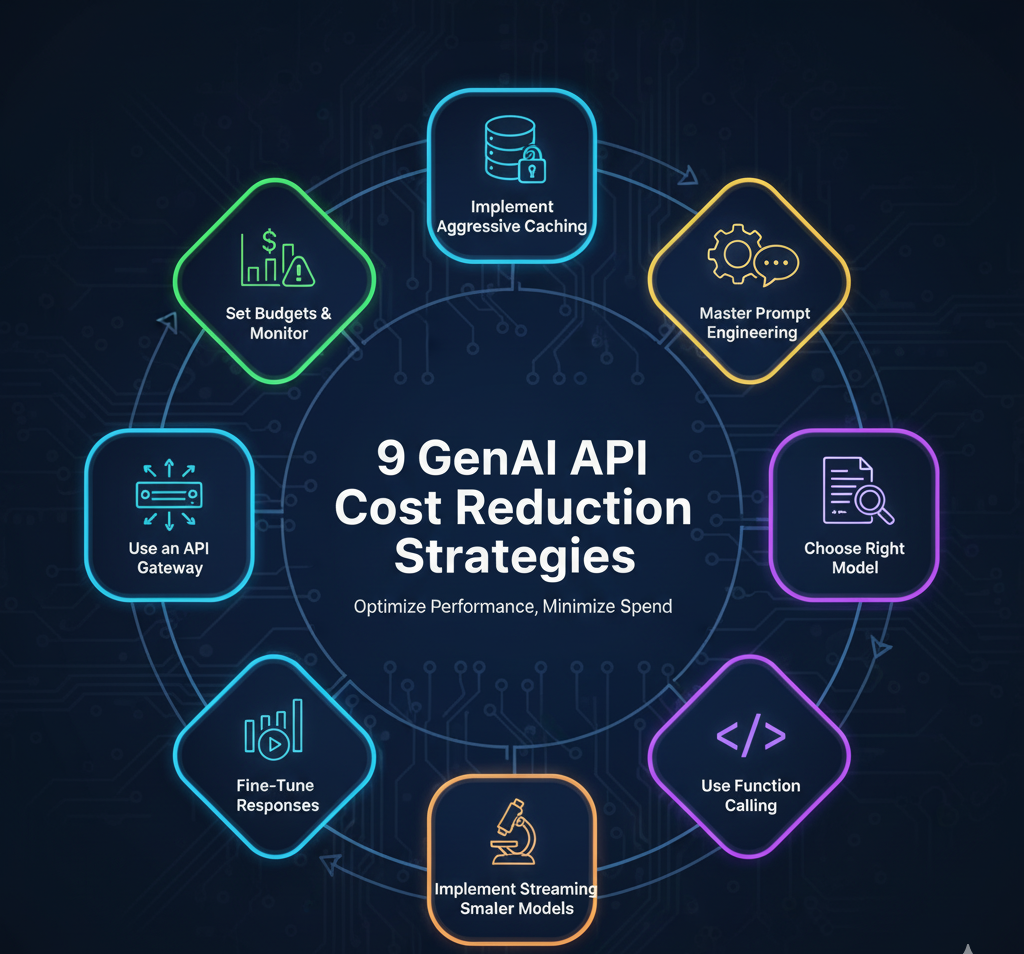
In this guide, we’ll provide a practical playbook for reducing your spend. Here are the 9 actionable strategies we will cover:
To effectively cut costs, you first need to understand exactly what you’re paying for. In the world of Large Language Models (LLMs), the currency is the token.
A token isn’t a word, but it’s close—think of it as a common piece of a word. On average, 100 tokens are about 75 English words. When you send a request to an API, the cost is calculated based on this simple formula:
Total Cost = (Number of Input Tokens × Price-per-Input-Token) + (Number of Output Tokens × Price-per-Output-Token)
There are two critical takeaways from this:
You pay for both input and output. A long, poorly written prompt is just as costly as a long, rambling response.
Input and output prices are often different. Many providers, like Anthropic with its powerful Claude 3 Opus model, charge significantly more for the tokens the model generates (output) than for the tokens you send it (input). This is because generation is a much more computationally intensive task.
Understanding this “token economy” is the foundation for every cost-saving strategy that follows. Every tip on this list is designed to minimize the number of input tokens, output tokens, or both.
9 Actionable Strategies for Reducing GenAI API Costs
Let’s dive into the practical techniques you can use to optimize your spending with providers like OpenAI, Anthropic, and Mistral.
1. Implement Aggressive Caching
What & Why: Caching is the lowest-hanging fruit in Reducing GenAI API Costs. The principle is simple: never ask the model the same question twice. If a user asks a question that has been answered before, you should store that answer in a temporary database (like Redis or Memcached) and serve the stored response directly instead of making another expensive API call.
How to Implement It: For a customer service chatbot, create a cache where the key is the user’s question (or a normalized version of it) and the value is the model’s generated answer. Before calling the LLM API, your application should first check if the answer already exists in the cache. This is incredibly effective for FAQ-style queries or common information requests.
Provider-Specific Nuance: This is a universal technique that works for any API provider and can often eliminate 20-30% of your API calls for high-volume, repetitive-query applications.
2. Master Prompt Engineering for Brevity
What & Why: The way you phrase your instructions to the model—your prompt—has a direct impact on your input token count. Prompt engineering for cost is about being as clear and concise as possible. Every unnecessary word or phrase in your prompt is a word you’re paying for.
How to Implement It: Instead of conversational, verbose prompts, use direct commands.
Instead of:“Hey there, could you please take a look at the following block of text and summarize it for me into about three main bullet points? Thanks!” (29 tokens)
Use:“Summarize the following text in three bullet points:” (8 tokens) This simple change reduces your input token count by over 70% for this instruction, a massive saving when scaled across millions of calls.
Provider-Specific Nuance: While all models benefit from brevity, models from providers like Mistral, which are often self-hosted and highly efficient, respond particularly well to direct, command-style prompts.
3. Control the Output Length with max_tokens
What & Why: Just as you can control your input, you must control your output. LLMs can be verbose. If you don’t give them a clear stopping point, they might generate far more text than you need, driving up your output token costs. The max_tokens parameter is your most direct tool for this.
How to Implement It: When making an API call, specify the maximum number of tokens you want in the response. If you’re generating a product title, you don’t need a 500-word essay. Set max_tokens: 20. If you need a one-sentence summary, set max_tokens: 30. This prevents budgetary leaks from unnecessarily long responses.
Provider-Specific Nuance: This is a standard parameter across almost all major API providers, including OpenAI and Anthropic. Using it is a fundamental best practice for GenAI token management.
4. Choose the Right Model for the Job (The 10x Cost Saver)
What & Why: This is arguably the most impactful cost-saving decision you can make. It’s tempting to always use the latest, most powerful flagship model (like GPT-4o or Claude 3 Opus), but these models are also the most expensive. For many tasks, a smaller, cheaper, and faster model is more than sufficient.
How to Implement It: Create a “model router” in your application. For simple, high-volume tasks like sentiment analysis, data classification, or simple Q&A, route the request to a cheaper model like GPT-3.5-Turbo, Claude 3 Haiku, or Mistral’s small models. Reserve the expensive flagship models only for complex reasoning, creative writing, or multi-step tasks.
Provider-Specific Nuance: The cost difference is staggering. As of mid-2025, according to Anthropic’s official pricing, Claude 3 Haiku is roughly 30 times cheaper than Claude 3 Opus for the same task. Similarly, OpenAI’s GPT-3.5-Turbo is significantly cheaper than GPT-4o. A thoughtful OpenAI cost optimization strategy always starts with model selection, A thoughtful OpenAI cost optimization strategy always starts with model selection, which requires a deep understanding of the trade-offs involved in comparing different AI capabilities.
5. Use Function Calling & Tool Use
What & Why: Sometimes, you need the model to have access to real-time, structured information. The naive approach is to paste all that information directly into the prompt. This is incredibly token-intensive and expensive. A much smarter way is to use “function calling” (in OpenAI’s terms) or “tool use” (in Anthropic’s terms), which allows the model to call external functions to retrieve data on its own.
How to Implement It: Instead of pasting a 1000-token weather report into the prompt and asking, “Should I wear a jacket in Thiruvananthapuram today?”, you define a function called get_current_weather(city). You then simply ask the model the question. The model will recognize it needs weather data, call your function, get back a tiny, structured response (e.g., {temp: 29, condition: “light rain”}), and then generate its answer. This reduces a huge prompt to a small one.
Provider-Specific Nuance: This is a key feature of modern models from OpenAI and Anthropic and is a game-changer for reducing GenAI API costs for data-intensive applications.
6. Fine-Tune a Smaller, Cheaper Model
What & Why: For very high-volume, domain-specific tasks, relying on a general-purpose API can become prohibitively expensive. Fine-tuning involves taking a smaller, more affordable model and training it further on your own data. The result is a specialized “expert” model that can outperform a massive general model on your specific task for a fraction of the inference cost.
How to Implement It: If you have a dataset of thousands of high-quality examples (e.g., customer support tickets and their resolutions), you can use it to fine-tune a model like GPT-3.5-Turbo or an open-source model from Mistral. The upfront cost of fine-tuning can be paid back quickly through the massive savings on every subsequent API call.
Provider-Specific Nuance: OpenAI offers a fine-tuning API for its smaller models. For maximum savings, you can fine-tune and self-host an open-source model like those from Mistral API efficiency experts.
7. Implement Streaming Responses
What & Why: Streaming doesn’t reduce the total number of tokens you pay for, but it’s a critical technique for managing costs indirectly by improving perceived performance. More powerful models are slower. Streaming sends the response back to the user token-by-token as it’s generated, so text appears on the screen immediately. This makes a slow model feel fast.
How to Implement It: Instead of a standard API call that waits for the full response, you open a streaming connection. This allows you to use a more capable (and perhaps more cost-effective in terms of quality) model without frustrating your users with long wait times, preventing the need to downgrade to a less effective but faster model.
Provider-Specific Nuance: All major providers, including OpenAI and Anthropic, support streaming responses. It’s essential for any real-time chat application.
8. Use an API Gateway
What & Why: As you start using multiple models from different providers, managing them can become complex. An API gateway or router (like LiteLLM or Portkey) acts as a single entry point for all your LLM calls. This allows you to enforce rules in one place.
How to Implement It: You can configure your gateway to automatically handle caching, retry failed requests, and, most importantly, route requests to the most cost-effective model that can handle the task. It can also enforce global max_tokens limits and provide unified logging and cost tracking across all providers.
Provider-Specific Nuance: This is a provider-agnostic strategy that simplifies LLM API cost savings when you’re operating in a multi-provider environment.
9. Set Budgets, Monitor, and Alert
What & Why: You cannot optimize what you cannot measure. The first step in preventing catastrophic overruns is to set hard limits and have an early warning system. Hope is not a strategy.
How to Implement It: Go into your OpenAI or Anthropic account dashboard and set hard and soft spending limits for the month. Soft limits should trigger email alerts to your engineering team, while hard limits will stop API calls entirely, preventing a runaway process from bankrupting you. Complement this with third-party GenAI cost monitoring tools for more granular insights, always keeping in mind theprivacy considerations of using third-party APIs.
Provider-Specific Nuance: This is a fundamental feature of any enterprise-ready API. Using the built-in billing controls is the bare minimum for responsible AI development.
Beyond the Code: Fostering a Culture of Cost Awareness
Reducing GenAI API Costs isn’t just a job for the engineering team; it requires a cultural shift. The most effective companies treat API cost as a key performance metric, just like user engagement or system uptime. Encourage your product managers and developers to think critically about every AI feature. A/B test different prompts and models to find the optimal balance between performance and cost. Create internal dashboards that don’t just show API usage, but translate it into business-relevant metrics like “Cost per Active User” or “Cost per Article Summarized.” When the entire team sees the financial impact of their decisions, they become empowered to innovate more efficiently.
Conclusion
The accessibility of modern GenAI APIs is a phenomenal opportunity, but it comes with the responsibility of smart management. Reducing GenAI API Costs is not about stifling innovation or using AI less; it’s about using it with intention and efficiency. By moving beyond the default settings and implementing a multi-layered strategy—from technical solutions like caching and function calling to strategic choices in model selection and prompt design—you can build incredible, performant AI features that are also financially sustainable, creating powerful business applications with a clear ROI.
This proactive approach to cost optimization ensures that your AI initiatives can scale effectively, providing long-term value without generating long-term financial headaches. If you’re looking to implement these strategies and build a truly cost-effective AI roadmap, you don’t have to do it alone. Here at Accubits, we specialize in architecting and optimizing GenAI solutions that deliver maximum performance at the lowest possible cost.