




Text to Image,
Stable Diffusion V1
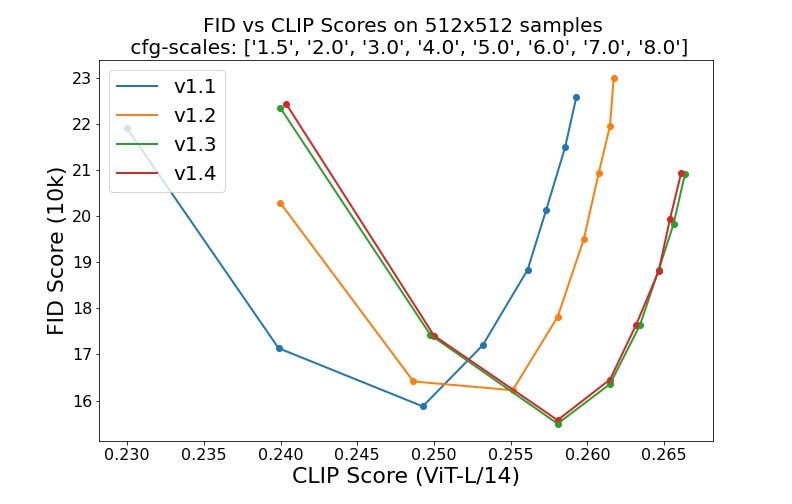
Stable Diffusion v1 is a text-to-image diffusion model that generates realistic images based on given text inputs. The Stable Diffusion v1.1 was trained on 237,000 steps at resolution 256x256 on laion2B-en, followed by 194,000 steps at resolution 512x512 on laion-high-resolution.
Model Card100+ Technical Experts

50 Custom AI projects
4.8 Minimum Rating
Blockchain Success Starts here
About Model
Stable Diffusion is an advanced model that converts text into highly realistic images. Using Latent Diffusion, you can generate photo-realistic images based on any given text input.
The training process for Stable-Diffusion-v1-1 involved 237,000 steps at a resolution of 256x256 on the dataset laion2B-en. Followed by an additional 194,000 steps at a resolution of 512x512 on the dataset lion-high-resolution, which consisted of 170 million examples from LAION-5B with a resolution of 1024x1024 or higher.
The model can generate and modify images based on text prompts. The Latent Diffusion Model uses a fixed, pretrained text encoder (CLIP ViT-L/14), as suggested in the Imagen paper.
Stable Diffusion V1 is under the CreativeML OpenRAIL M license, adapted from the work that BigScience and the RAIL Initiative are jointly carrying in responsible AI licensing.
Developed by: CompVis (Robin Rombach, Patrick Esser)
Model type: Diffusion-based text-to-image generation model
Language(s): English


Other LLMs

PFGM++
PFGM++ is a family of physics-inspired generative models that embeds trajectories for N dimensional data in N+D dimensional space using a simple scalar norm of additional variables.
Read More

MDT-XL2
MDT proposes a mask latent modeling scheme for transformer-based DPMs to improve contextual and relation learning among semantics in an image.
Read More

Stable Diffusion
An image synthesis model called Stable Diffusion produces high-quality results without the computational requirements of autoregressive transformers.
Read More