



Text to Image
Stable Diffusion V2
Stable Diffusion v2 refers to a specific configuration of the model architecture that uses a downsampling-factor 8 autoencoder with an 865M UNet and OpenCLIP ViT-H/14 text encoder for the diffusion model. The SD 2-v model produces 768x768 px outputs.
Model Card100+ Technical Experts

50 Custom AI projects
4.8 Minimum Rating
Blockchain Success Starts here
About Model
Stable Diffusion is an advanced model that converts text into highly realistic images. Using Latent Diffusion, you can generate photo-realistic images based on any given text input. Stable Diffusion v2 refers to a specific configuration of the model architecture that uses a downsampling-factor 8 autoencoder with an 865M UNet and OpenCLIP ViT-H/14 text encoder for the diffusion model. The SD 2-v model produces 768x768 px outputs.
Developed by: Robin Rombach, Patrick Esser
Model type: Diffusion-based text-to-image generation model
Language(s): English
| Checkpoint | Details |
| 512-base-ema.ckpt | dimension550k steps at resolution 256x256 on a subset of LAION-5B filtered for explicit pornographic material, using the LAION-NSFW classifier with punsafe=0.1 and an aesthetic score >= 4.5. 850k steps at resolution 512x512 on the same dataset with resolution >= 512x512. |
| 768-v-ema.ckpt | Resumed from 512-base-ema.ckpt and trained for 150k steps using a v-objective on the same dataset. Resumed for another 140k steps on a 768x768 subset of our dataset. |
| 512-depth-ema.ckpt | Resumed from 512-base-ema.ckpt and finetuned for 200k steps. Added an extra input channel to process the (relative) depth prediction produced by MiDaS (dpt_hybrid) which is used as an additional conditioning. The additional input channels of the U-Net which process this extra information were zero-initialized. |
| 512-inpainting-ema.ckpt | Resumed from 512-base-ema.ckpt and trained for another 200k steps. Follows the mask-generation strategy presented in LAMA which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning. The additional input channels of the U-Net which process this extra information were zero-initialized. The same strategy was used to train the 1.5-inpainting checkpoint. |
| x4-upscaling-ema.ckpt | Trained for 1.25M steps on a 10M subset of LAION containing images >2048x2048. The model was trained on crops of size 512x512 and is a text-guided latent upscaling diffusion model. In addition to the textual input, it receives a noise_level as an input parameter, which can be used to add noise to the low-resolution input according to a predefined diffusion schedule. |

Results
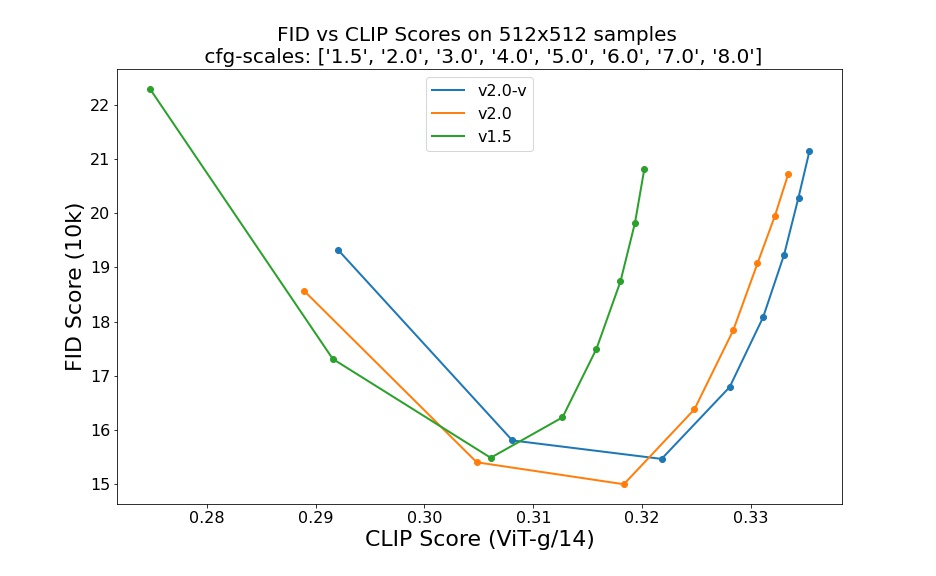
Stable Diffusion v2 refers to a specific configuration of the model architecture that uses a downsampling-factor 8 autoencoder with an 865M UNet and OpenCLIP ViT-H/14 text encoder for the diffusion model. The SD 2-v model produces 768x768 px outputs. Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0) and 50 DDIM sampling steps show the relative improvements of the checkpoints:
Examples

Other LLMs

PFGM++
PFGM++ is a family of physics-inspired generative models that embeds trajectories for N dimensional data in N+D dimensional space using a simple scalar norm of additional variables.
Read More

MDT-XL2
MDT proposes a mask latent modeling scheme for transformer-based DPMs to improve contextual and relation learning among semantics in an image.
Read More

Stable Diffusion
An image synthesis model called Stable Diffusion produces high-quality results without the computational requirements of autoregressive transformers.
Read More