




T2I Models Explained,
INDM
The Implicit Nonlinear Diffusion Model (INDM) uses a normalizing flow to transform a linear latent diffusion to the data space, enabling nonlinear inference. INDM has advantages over other models, including fast optimization, learning of drift and volatility coefficients, MLE training, and robustness in sampling discretization.
Model Card100+ Technical Experts

50 Custom AI projects
4.8 Minimum Rating
An Overview of INDM
The Implicit Nonlinear Diffusion Model (INDM) uses a normalizing flow to transform a linear latent diffusion to the data space, enabling nonlinear inference.

INDM outperforms DDPM++ and achieves a SOTA FID
1.75 FID Score
INDM surpasses DDPM++ and attains the highest FID score of 1.75 on the CelebA dataset, setting a new state-of-the-art benchmark.
The CIFAR-10 dataset has 50,000 training images.
50K Images
The CIFAR-10 dataset comprises a total of 50,000 images that are used for training Implicit Nonlinear Diffusion Models.
INDM has set new benchmarks for image generation
SOTA Results
INDM has achieved state-of-the-art results on various image generation benchmarks, including CelebA and LSUN.
Blockchain Success Starts here
About Model
The Implicit Nonlinear Diffusion Model (INDM) uses a flow network and diffusion process to learn. INDM creates a flexible nonlinearity in data space by using a linear diffusion on the latent space. INDM outperforms DDPM++ and achieves a state-of-the-art FID of 1.75 on CelebA.

Training Details
Training data
The authors used the CIFAR-10 dataset to train their model.


Training dataset size
The CIFAR-10 dataset has 50,000 training images.
Training Procedure
The authors used maximum likelihood estimation (MLE) to train their Implicit Nonlinear Diffusion Model (INDM).
Training time and resources
The authors reported a training time of about 3 days using 8 GPUs for their experiments.
| Task | Dataset | Score |
| Image Generation (VP, FID) | CelebA 64x64 | 1.75 |
| Image Generation (VE, FID) | CelebA 64x64 | 2.54 |
| Image Generation (VP, NLL) | CelebA 64x64 | 3.06 |
| Image Generation (ST) | CIFAR-10 | 3.25 |
| Image Generation (NLL) | CIFAR-10 | 4.79 |
| Image Generation (FID) | CIFAR-10 | 2.28 |
| Image Generation (VE,FID) | CIFAR-10 | 2.29 |
| Image Generation (VP,FID) | CIFAR-10 | 2.9 |
| Image Generation (VP,NLL) | CIFAR-10 | 5.3 |
| Tasks | Business Use Cases | Examples |
| Image Generation and Restoration | Image and video processing, Medical imaging, Media and Entertainment | Image denoising, Super-resolution, Deblurring |
| Facial Attribute Recognition | Security and surveillance, Advertising, Healthcare | Facial recognition, Emotion detection, Age and gender estimation |
| Image Classification | Autonomous vehicles, Healthcare, E-commerce | Object detection and recognition, Disease diagnosis, Product categorization |
Benchmark Results
Benchmarking is an important process to evaluate the performance of any language model, including INDM. The key results are;
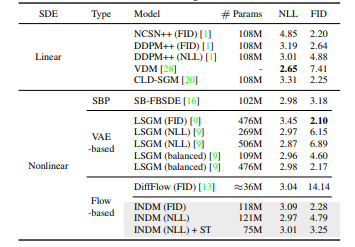
Performance comparison on CIFAR-10.
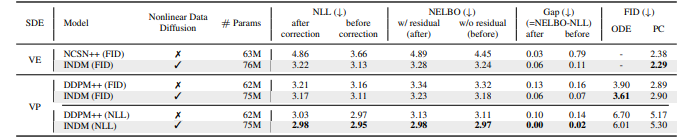
Performance comparison to linear/nonlinear diffusion models on CIFAR-10. We report the performance of linear diffusions by training our PyTorch implementation based on Song et al. [1, 11] with identical hyperparameters and score networks on both linear/nonlinear diffusions to quantify the effect of nonlinearity in a fair setting. Boldface numbers represent the best performance in a column.
Other LLMs

PFGM++
PFGM++ is a family of physics-inspired generative models that embeds trajectories for N dimensional data in N+D dimensional space using a simple scalar norm of additional variables.
Read More

MDT-XL2
MDT proposes a mask latent modeling scheme for transformer-based DPMs to improve contextual and relation learning among semantics in an image.
Read More

Stable Diffusion
An image synthesis model called Stable Diffusion produces high-quality results without the computational requirements of autoregressive transformers.
Read More