LLMs Explained,
GLaM
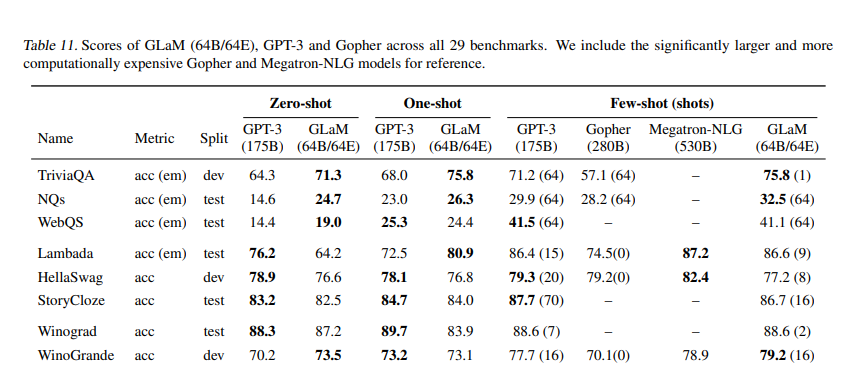
GLaM, Generalist Language Model, is a trillion-weight model introduced by Google. It achieves competitive performance on multiple few-shot learning tasks. Its performance is comparable to GPT-3. It has significantly improved learning efficiency across 29 public NLP benchmarks in seven categories. Based on the Transformer architecture, the model is pre-trained on a large corpus of text data using unsupervised learning. This pre-training enables the model to learn natural language patterns and structures, which it can then apply to various downstream tasks.
Model Card100+ Technical Experts

50 Custom AI projects
4.8 Minimum Rating
An Overview of GLaM
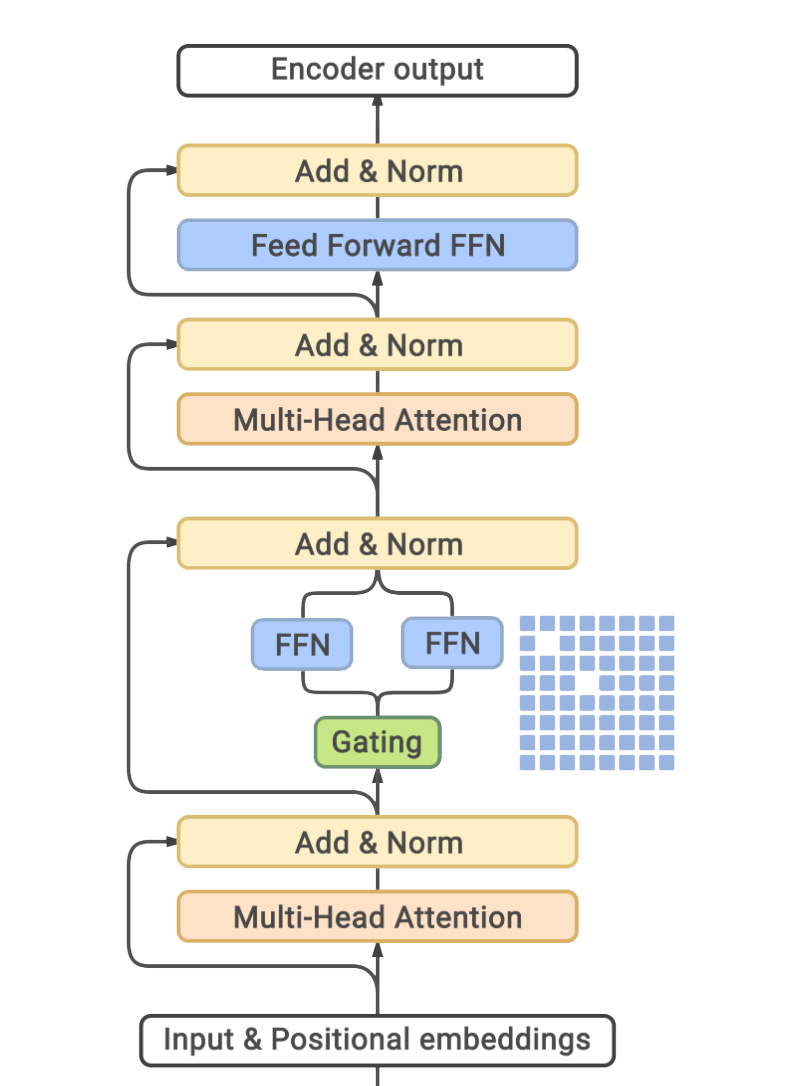
GLaM is a mixture of experts model, a model that can be thought of as having different submodels, each specialized for different inputs.

GLaM is approximately 7x larger than GPT-3
1.2 Trillion Parameters
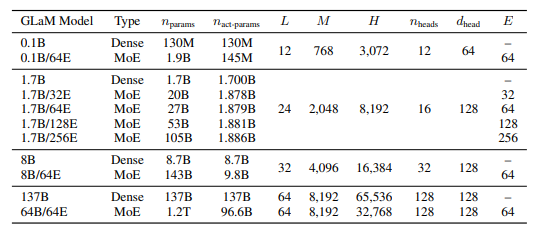
The largest GLaM has 1.2 trillion parameters, and it is approximately 7x larger than GPT-3.
Less training cost, less energy consumption
Relatively Energy Efficient
GLaM consumes only 1/3 of the energy used to train the GPT-3 model and requires half of the computation flops for inference.
Better performance with less computation
Excelled in 29 NLP tasks
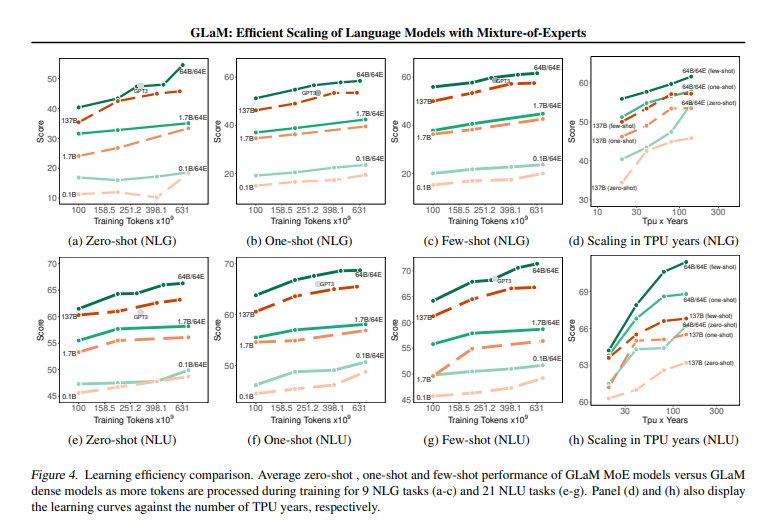
The model achieves better overall zero, one, and few-shot performance across 29 NLP tasks.
Blockchain Success Starts here
Introduction to GLaM
GLaM is a mixture of expert (MoE) models, which can be thought of as having different submodels specialized for different inputs. The full version of the model has 1.2T total parameters across 64 experts per MoE layer with 32 MoE layers in total. It only activates a subnetwork of 97B parameters per token prediction during inference. The model has shown significantly improved learning efficiency across 29 public NLP benchmarks in seven categories, including language completion, open-domain question answering, and natural language inference tasks.


Training Details
Training data
Most of the information comes from web pages, including professional writing and low-quality comment and forum pages. The GLaM team created its text quality classifier to ensure the quality of the web pages in the dataset. This classifier detects and categorizes high-quality web pages in a larger raw corpus of web pages.


Training Procedure
The GLaM model is trained on multiple GPUs using a distributed training approach, allowing faster and more efficient training. Iterative training minimizes the loss function, with the model's parameters updated after each iteration. The final trained model is then assessed on various downstream tasks to determine its performance and generalization ability.
Training dataset size
The training dataset of the GLaM model contains 1.6 trillion tokens. It is a is a massive dataset that is significantly larger than most other language models currently available. According to the paper's authors, the size of this massive dataset is critical for ensuring that the model generalizes well across a wide range of natural language use cases.
Training time and resources
The original paper does not specify a training time for GLaM, but it does state that the model was trained on a cluster of GPUs using a distributed training approach. The model was specifically trained on a cluster of 1,024 Nvidia V100 GPUs, a powerful computing resource commonly used for large-scale deep learning applications.
| Language Modeling | Multilingual NLP |
| Text completion and prediction | Multilingual customer support |
| Sentiment analysis | Multilingual chatbots and virtual assistants |
| Text classification | Multilingual sentiment analysis |
| Language translation | Multilingual social media monitoring |
| Content generation and summarization | Multilingual search engines |
| Speech recognition and transcription | Multilingual voice assistants and speech recognition |
| Personalization and recommendation systems | Multilingual voice assistants and speech recognition |
| Information retrieval and search engines | Multilingual text summarization and classification |
| Fraud detection and spam filtering. | Multilingual data analysis and visualization |
Model Tasks

Machine translation
The GLaM model can also be used for machine translation, translating text from one language to another. This complex task involves many different components, but the GLaM model can be a useful part of the overall system.
Text completion
This task involves predicting the next word or words in a sentence or phrase. The GLaM model can be trained to suggest the most likely next word based on the context of the sentence.
Dialogue generation
This task involves generating a natural-sounding dialogue between two or more speakers. The GLaM model can be trained to generate responses that are appropriate to the context of the conversation.
Natural language inference
In this task, the GLaM model is used to determine whether a statement logically follows from another statement. GLaM can be useful for tasks like fact-checking or automated reasoning.
Document clustering
In this task, the GLaM model groups similar documents based on their content. This model can be useful for tasks like information retrieval or text analysis.