



LLMs Explained,
Megatron
Megatron is a powerful language model developed by NVIDIA, specifically designed for training large-scale natural language processing (NLP) models. The model's name is inspired by the nefarious robot character from the Transformers franchise, which symbolizes its ability to adapt and expand to handle vast amounts of data and complex language-related tasks. By leveraging advanced hardware and software technologies, Megatron can efficiently process massive amounts of data and learn from diverse linguistic patterns, resulting in impressive language generation capabilities. Its name not only reflects its technological prowess but also suggests the transformative impact that it can have on the field of NLP.
Model Card100+ Technical Experts

50 Custom AI projects
4.8 Minimum Rating
An Overview of Megatron
Megatron is a powerful language model developed by NVIDIA, specifically designed for training large-scale natural language processing (NLP) models.

Scales up to 8.3billion parameters
8.3b parameters
Megatron 8.3B contains 8.3 billion parameters, making it one of the largest language models in the world.
7 times faster and efficient than other models
7X faster
Megatron can train models up to 7 times faster than T5, allowing for faster experimentation and iteration.
94.5% on the Stanford Question Answering Dataset
94.5% Accuracy
The paper shows Megatron achieved an accuracy of 94.5% on SQuAD v1.1 task, and 80.4% score in Natutal language processing tasks.
Blockchain Success Starts here
About Model
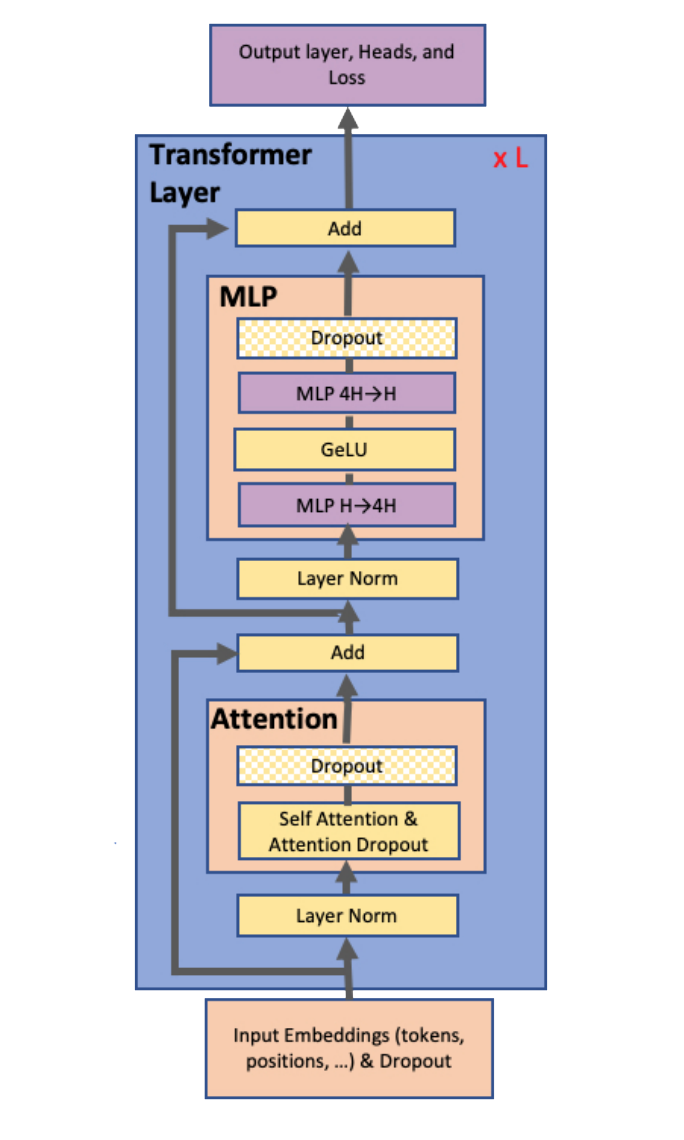
The Megatron model includes feedforward and normalization layers, which aid the model's performance and stability during training. Megatron is built to be highly scalable, allowing it to be trained on massive amounts of data with distributed computing techniques like data parallelism and model parallelism. Megatron achieves scalability by combining model parallelism and data parallelism. Data parallelism involves splitting the training data across multiple GPUs or machines, whereas model parallelism involves splitting the model across multiple GPUs or machines. Megatron can be trained using various optimization techniques such as stochastic gradient descent (SGD), Adam, and Adafactor. Megatron has been used for various NLP tasks other than language modeling, such as answering questions and machine translation.
Model Type: Deep learning model
Language(s) (NLP): English, Spanish, French, German, Chinese, Arabic, and so on.
License: Apache 2.0


Training Details
Training data
The training data for Megatron LM was sourced from various outlets such as web pages, books, and Wikipedia. It totaled 8.3 terabytes with 40 billion+ tokens. The data was preprocessed with byte-pair encoding (BPE) to divide words into subword units. Segments of 512 tokens were created from the preprocessed data and were further broken down to speed up processing.


Training Procedure
The research paper details the training process for Megatron LM. PyTorch and NCCL were used for parallel training, combining model parallelism and data parallelism. Unsupervised pretraining and supervised fine-tuning were used for training, with varying precision levels. Gradient checkpointing and gradient accumulation were also used to manage memory usage.
Training dataset size
The size of the training dataset used for Megatron LM was approximately 8.3 terabytes, consisting of over 40 billion tokens. The vast size of the training dataset is crucial for enabling Megatron to learn from a vast array of linguistic contexts and patterns, allowing it to capture a broad range of syntactic and semantic structures, as well as world knowledge.
Training time and resources
The research paper doesn't provide a specific training time for Megatron LM. However, the model was trained on 1,024 GPUs using a combination of model parallelism and data parallelism. The training process employed various techniques like precision levels, gradient checkpointing, and gradient accumulation to manage memory usage.
| Model | Parameters | Highlights |
| Megatron-LM | 3.6 billion | Trained on a dataset of over 8 million web pages. |
| Megatron-XL | 5.8 billion | Trained on over 40GB of text dataset. |
| Megatron-11B | 11 billion | Trained on a massive dataset of over 800 billion tokens. |
| Language Modelling | Reading Comprehension | Question Answering |
| Text generation for content creation | Chatbots for customer support | Customer service chatbots to answer frequently asked questions |
| Predictive text and autocorrect in messaging apps | Automated news summarization and article extraction | Automated customer surveys to gather feedback |
| Sentiment analysis for customer feedback and social media monitoring | Intelligent personal assistants for scheduling and information retrieval | Search engine optimization for improving search results |
Model Tasks
Megatron is a general-purpose language model architecture that can be used for a wide range of natural language processing (NLP) tasks. Here are some tasks that Megatron can perform:

Language Modeling
Megatron can be trained to predict the probability distribution of the next word in a sequence of text, which is the task of language modeling. This is typically done by training the model on a large corpus of text data and then using it to generate new text that is coherent and consistent with the input data.
Text Generation
Megatron can be used for text generation tasks, such as machine translation, summarization, and dialogue generation. This involves training the model to generate coherent and natural-sounding text responding to a given prompt or input.
Question Answering
Megatron can be trained to answer questions based on a given context, which is the task of question answering. This involves training the model to extract relevant information from the input text and generate a natural-language answer to a given question.
Sentiment Analysis
Megatron can be used for sentiment analysis tasks, such as the classification of text into positive, negative, or neutral categories. This involves training the model to recognize patterns in the input text indicative of different sentiments.
Named Entity Recognition
Megatron can be trained to identify and extract named entities from text, such as people, places, and organizations. This involves training the model to recognize patterns in the input text indicative of named entities.
Text Classification
Megatron can be used for text classification tasks, such as spam detection or topic classification. This involves training the model to recognize patterns in the input text indicative of different categories.
| Model | Trained Tokens Ratio | MNLI m/mm Accuracy (Dev Set) | QQP Accuracy (Dev Set) | SQuAD 1.1 F1 / EM (Dev Set) | SQuAD 2.0 F1 / EM (Dev Set) | RACE Accuracy (test set) |
| RoBERTa | 2 | 90.2 / 90.2 | 92.2 | 94.6 / 88.9 | 89.4 / 86.5 | 83.2 (86.5 / 81.8) |
| ALBERT | 3 | 90.8 | 92.2 | 94.8 / 89.3 | 90.2 / 87.4 | 86.5 (89.0 / 85.5) |
| XLNet | 2 | 90.8 / 90.8 | 92.3 | 95.1 / 89.7 | 90.6 / 87.9 | 85.4 (88.6 / 84.0) |
| Megatron-336M | 1 | 89.7 / 90.0 | 92.3 | 94.2 / 88.0 | 88.1 / 84.8 | 83.0 (86.9 / 81.5) |
| Megatron-1.3B | 1 | 90.9 / 91.0 | 92.6 | 94.9 / 89.1 | 90.2 / 87.1 | 87.3 (90.4 / 86.1) |
| Megatron-3.9B | 1 | 91.4 / 91.4 | 92.7 | 95.5 / 90.0 | 91.2 / 88.5 | 89.5 (91.8 / 88.6) |
| ALBERT ensemble | - | - | - | 95.5 / 90.1 | 91.4 / 88.9 | 89.4 (91.2 / 88.6) |
| Megatron-3.9B ensemble | - | - | - | 95.8 / 90.5 | 91.7 / 89.0 | 90.9 (93.1 / 90.0) |
| Model | ARC-Challenge | ARC-Easy | RACE - middle | RACE - high | Winogrande | RTE | BoolQA | HellaSwag | PiQA |
| Megatron-GPT 20B | 0.4403 | 0.6141 | 0.5188 | 0.4277 | 0.659 | 0.5704 | 0.6954 | 0.721 | 0.7688 |
| Megatron-GPT 1.3B | 0.3012 | 0.4596 | 0.459 | 0.3797 | 0.5343 | 0.5451 | 0.5979 | 0.4443 | 0.6934 |
| Megatron-GPT 5B | 0.3976 | 0.5566 | 0.5007 | 0.4171 | 0.6133 | 0.5812 | 0.6356 | 0.6298 | 0.7492 |


