LLMs Explained,
T5
The Text-to-Text Transfer Transformer (T5) is a cutting-edge text-to-text transformer model developed by Google Research and published in a research paper in October 2019. T5 is based on the transformer architecture, which Vaswani et al. introduced in their seminal paper "Attention Is All You Need" in 2017. Because of its effectiveness and scalability, the transformer architecture has since become the standard for many NLP tasks. T5 employs a unified framework that can convert any text-based language problem to a text-to-text format. This allows the model to be trained on various NLP tasks, including machine translation, document summarization, question answering, and classification tasks, using the same model, loss function, and hyperparameters.
Model Card100+ Technical Experts

50 Custom AI projects
4.8 Minimum Rating
An Overview of T5
T5 is a cutting-edge natural language processing model designed as a text-to-text framework for various NLP tasks such as machine translation, summarization, question answering, and classification. Here are some of the model's key features.

Largest T5 variant has 11 billion parameters
11B parameters
The largest T5 model variant, T5-11B, has 11 billion parameters. The larger models are more powerful but also require more computational resources to train and use.
T5 model was trained on a massive dataset
750GB Data
750GB massive dataset used to train the T5 model is known as the "Colossal Clean Crawled Corpus" (C4) and is one of the largest publicly available text corpora.
General language learning abilities
Performance
The model has shown good performance on a diverse set of benchmarks, including machine translation, question answering, abstractive summarization, and text classification
Blockchain Success Starts here
About Model
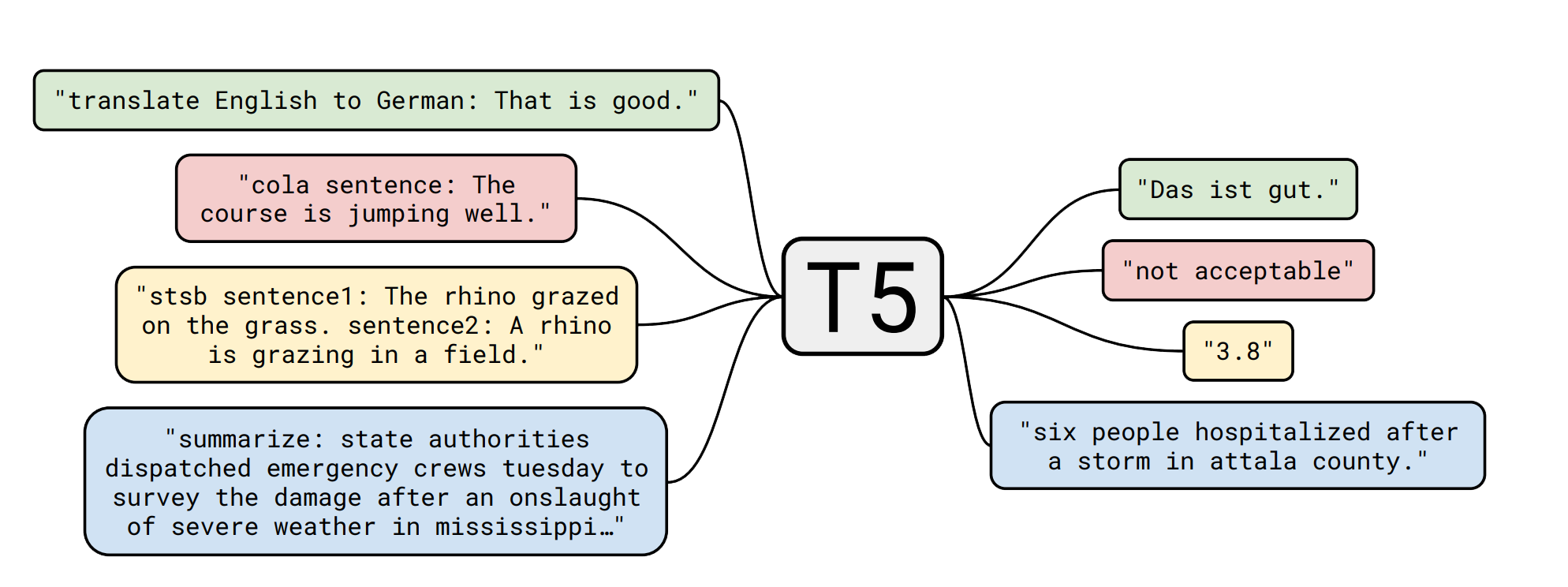
T5 is a text-to-text transformer model that employs a unified framework to handle text-based language tasks, making it versatile and powerful for NLP. T5 comes in several sizes, ranging from T5-Base to T5-11B, and is widely used in industry and academia for various NLP tasks. The model computes representations of input sequences using self-attention mechanisms. It employs the sequence-to-sequence (seq2seq) method, in which an input sequence is encoded into a fixed-length vector representation and decoded into an output sequence. T5's encoder and decoder are made up of multiple layers of transformers, which allows it to capture long-range dependencies and perform well on tasks that require advanced reasoning and inference skills. T5 is available in sizes ranging from 220 million to 11 billion parameters. Larger models are more powerful but also require more computational resources to train and use. T5 is used in the Hugging Face Transformers library, which has become one of the most popular and widely used NLP libraries.
Model Type: Language model
Language(s) (NLP): English, German, French, and Romanian
License: Apache 2.0


Training Details
Training data
For unsupervised denoising objective: C4, Wiki-DPR. For supervised text-to-text language modeling objective: CoLA, SST-2, MRPC, STS-B, QQP, MNLI, QNLI, RTE, CB, COPA, WIC, MultiRC, ReCoRD, BoolQ


Dataset size
The training dataset was a collection of text that is not only orders of magnitude larger than most data sets used for pre-training (about 750 GB) but also comprises reasonably clean and natural English text.
Training Procedure
T5 is trained to predict missing tokens in a sequence using a masked language modeling objective. This entails masking out tokens in the input sequence at random and training the model to predict the masked tokens.
Training Observations
Researchers find that pre-training provides significant gains across almost all benchmarks. The only exception is WMT English to French, which is a large enough data set that gains from pre-training tends to be marginal.
Model Types
There are several versions of the T5 model that have been trained on the same dataset. Here are the variations of the T5 model based on parameter count:
| Model | Parameters | Highlights |
| T5-Small | 60 million | NLP tasks |
| T5-Base | 220 million | general-purpose language processing |
| T5-Large | 770 million | higher accuracy or more complex NLP |
| T5-3B | 3 billion | high accuracy on complex and large-scale NLP tasks |
| T5-11B | 11 billion | specialized applications that need powerful NLP models. |
Google has released some follow-up works based on the original T5 model. Each of these have specialised on different NLP capabilities.
| Adaptions | Details |
| T5v1.1 | The improved version of T5 with some architectural tweaks is pre-trained on C4 only without mixing in the supervised tasks. |
| mT5 | Multilingual T5 model pre-trained on the mC4 corpus, which includes 101 languages. |
| byT5 | T5 model pre-trained on byte sequences rather than SentencePiece subword token sequences. |
| UL2 | Model similar to T5, pretrained on various denoising objectives |
| Flan-T5 | The Flan-T5 are T5 models trained on the Flan collection of datasets. Flan is a prompt-based pretraining method. |
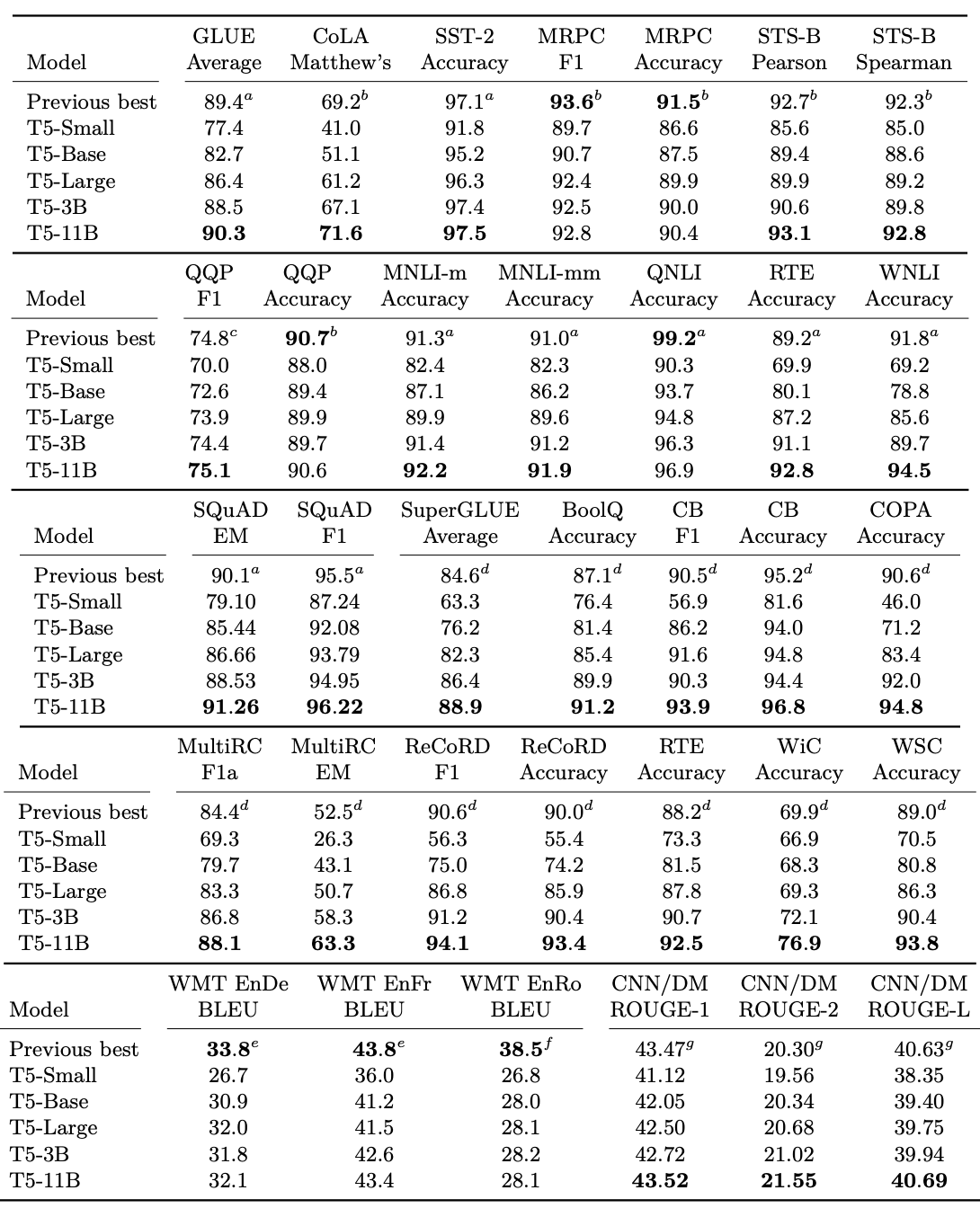
| GLUE | CNNDM | SQuAD | SGLUE | EnDe | EnFr | EnRo | |
| * Baseline average | 83.28 | 19.24 | 80.88 | 71.36 | 26.98 | 39.82 | 27.65 |
| Baseline standard deviation | 0.235 | 0.065 | 0.343 | 0.416 | 0.112 | 0.090 | 0.108 |
| No pre-training | GLUE | CNNDM | SQuAD | SGLUE | EnDe | EnFr | EnRo |
Table below shows the performance of T5 variants on various tasks.