LLMs Explained,
Bloom
The BigScience research workshop unveiled the BigScience Large Open-science Open-access Multilingual Language Model, a.k.a. Bloom. The model is based on the GPT-3 architecture, and it has been trained on an impressive dataset that includes 46 natural languages and 13 programming languages. This state-of-the-art language model has significantly advanced natural language processing (NLP) techniques. Bloom is the first AI language model to have over 100 billion parameters for most of the languages in the dataset. Although BigScience is currently evaluating the model, early results suggest that Bloom can perform several natural language processing (NLP) tasks with zero-shot learning.
Model Card100+ Technical Experts

50 Custom AI projects
4.8 Minimum Rating
An Overview of Bloom
Bloom is an autoregressive language model trained on an impressive dataset that includes 46 natural languages and 13 programming languages. It was developed by collaborating with hundreds of researchers from various organizations, including Facebook AI Research, Stanford University, and New York University.

It is one of the largest open-access language models available.
176B parameters
Bloom is one of the largest language models with 176B parameters, publicly released under the Responsible AI License and freely available to the public.
The model is trained on 46 natural and 13 programming languages.
Trained on 59 Languages
Bloom model was trained on the ROOTS corpus, which is a dataset that includes hundreds of sources in 46 natural and 13 programming languages.
Compared to similar models, CO2 emission is very low (25 tons)
25 tons CO2eq Emissions
Bloom is trained on a low carbon intensity energy grid resulting in 25 tons of CO2 emissions. It is one of the greenest compared to similar models.
Blockchain Success Starts here
About Model
BLOOM is an autoregressive Large Language Model. It can generate coherent and meaningful text, making it suitable for various applications. Bloom was trained on a massive multilingual corpus of text data totaling 1.6 terabytes and 350 billion tokens. One of Bloom's distinguishing features is its ability to perform zero-shot learning on various natural language processing (NLP) tasks. It can perform well on tasks for which it was not specifically trained. BLOOM was trained over almost four months using a cluster of 416 A100 80GB GPUs. The training process was open to the public, with logs available for viewing on TensorBoard. BLOOM was trained with 176 Billion parameters and a multilingual dataset. BLOOM is a decoder-only Transformer language model trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). The model achieves competitive performance on various benchmarks, with stronger results after undergoing multitask-prompted finetuning. The development was coordinated by BigScience, an open research collaboration whose goal was the public release of an LLM.


Training Details
Training data
Bloom is trained on 46 natural languages and 13 programming languages. The dataset had 1.6TB of pre-processed text converted into 350B unique tokens.


Training dataset size
Bloom is trained on a large dataset. Its Bf16 weights 329GB, and the full checkpoint with optimizer states was 2.3TB. The dataset vocabulary size was 250,680.
Training Procedure
BLOOM's learned subword tokenizer is trained using a byte-level Byte Pair Encoding (BPE) algorithm and a simple pre-tokenization rule with no normalization.
Training time and resources
Training the model took about 4 months. Training throughput was about 150 TFLOP per GPU per second and the estimated cost of model training was $2-5M.
| Model | Parameters |
| bloom-560m | 560 Million |
| bloom-1b1 | 1 Billion parameters |
| bloom-1b7 | 1.7 Billion parameters |
| bloom-3b | 3 Billion |
| bloom-7b1 | 7 Billion |
| bloom 176B | 176 Billion |
| Language Modeling | Multilingual NLP |
| Text completion and prediction | Multilingual customer support |
| Sentiment analysis | Multilingual chatbots and virtual assistants |
| Text classification | Multilingual sentiment analysis |
| Language translation | Multilingual social media monitoring |
| Content generation and summarization | Multilingual search engines |
| Speech recognition and transcription | Multilingual voice assistants and speech recognition |
| Personalization and recommendation systems | Multilingual voice assistants and speech recognition |
| Information retrieval and search engines | Multilingual text summarization and classification |
| Fraud detection and spam filtering. | Multilingual data analysis and visualization |
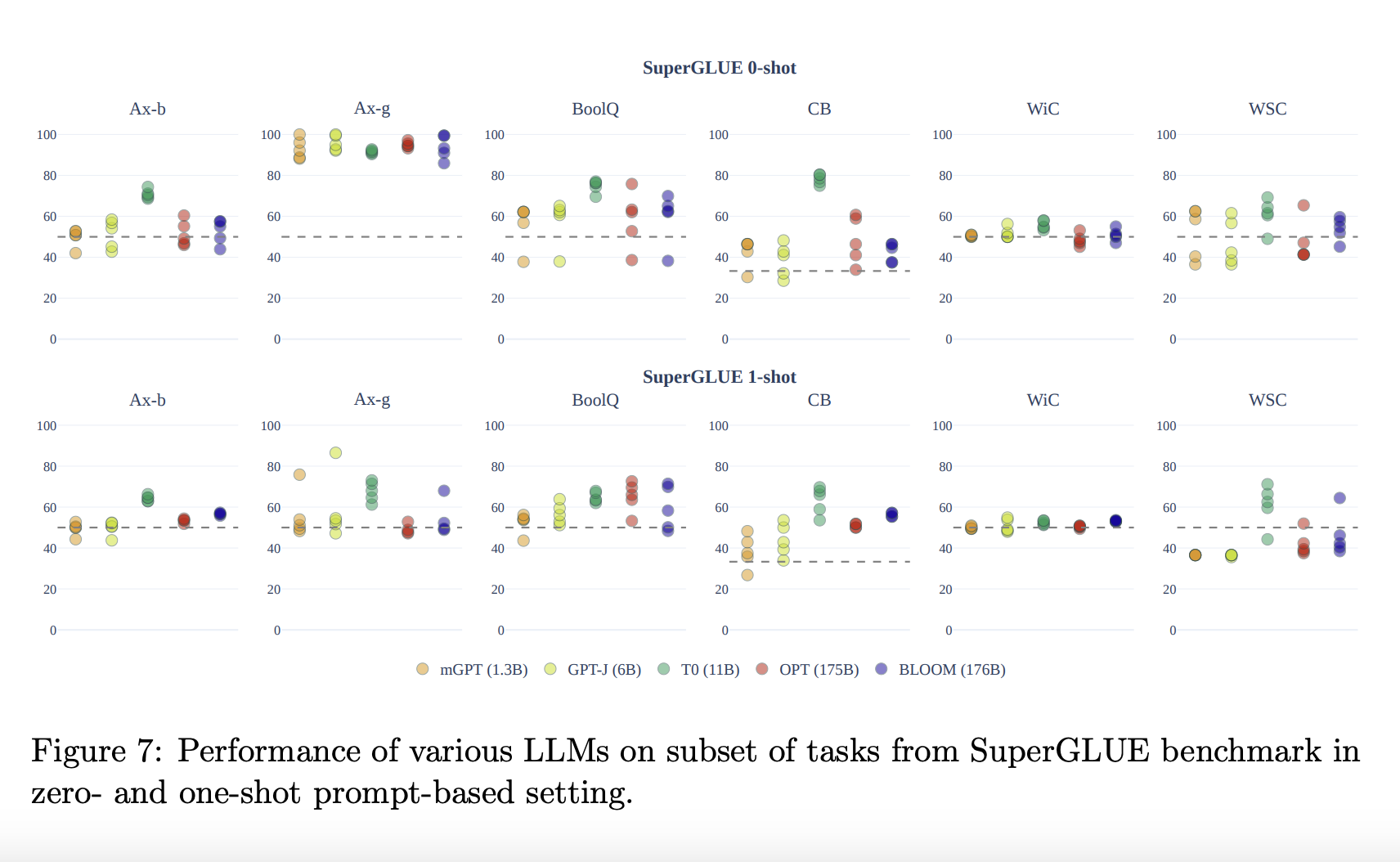
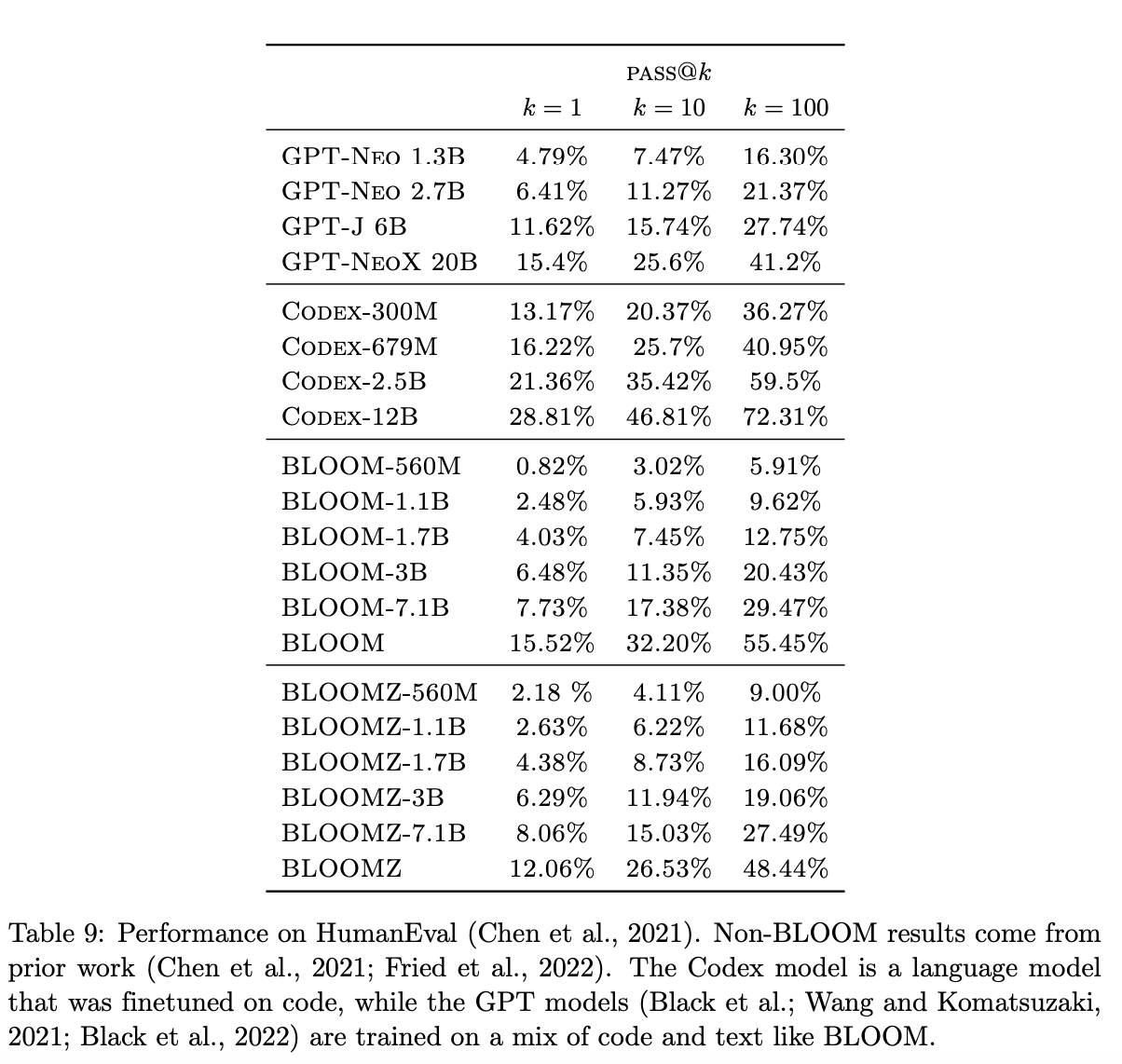
Key Benchmark Results