LLMs Explained,
Long T5
Long T5 is a pre-trained language model that extends Google Research's T5 architecture. It can generate longer and more coherent text than previous models and has demonstrated promising results in various language tasks such as question answering, summarization, and dialogue generation. Long T5 was trained on a large-scale dataset of diverse text sources. Long T5 is publicly available through the Hugging Face Transformers library, which provides pre-trained checkpoints and fine-tuning scripts for various downstream tasks. The model can be fine-tuned on custom datasets and tasks, making it a versatile tool for natural language processing applications.
Model Card100+ Technical Experts

50 Custom AI projects
4.8 Minimum Rating
An Overview of Long T5
Long T5 has outperformed previous models on several benchmark datasets, demonstrating its ability to generate longer, more coherent text.

Trained on dataset of over 800GB of text data
800GB text data
Long T5 is trained on a massive dataset of over 800GB of text data from diverse sources, including Wikipedia, books, and web pages.
11 times more parameters than its predecessor
11x more parameters
Long T5 has 11x more than its predecessor. The increased number of parameters allows capturing of complex patterns in natural language.
Long T5 can perform zero-shot learning
Zero-shot learning
Long T5 can generate responses for unseen prompts in the Persona-Chat dialogue generation dataset and can generates text for tasks it was yet to be explicitly trained on.
Blockchain Success Starts here
-
Introduction
-
Model Tasks
About Model
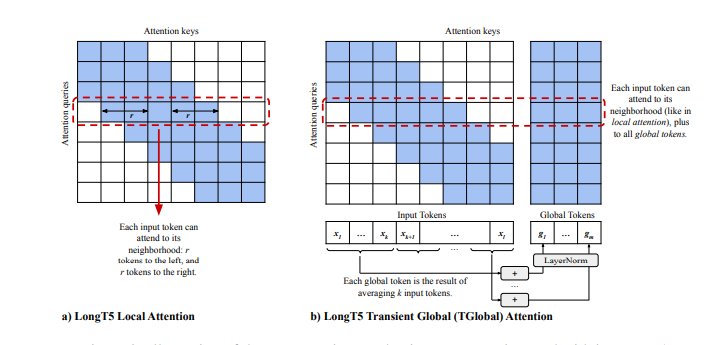
Long T5 employs a modified T5 architecture comprised of an encoder and a decoder. The encoder is responsible for processing the input text, while the decoder produces the output text. The input and output text is represented as token sequences that are mapped to high-dimensional vectors with the help of an embedding layer.
The encoder is built up of convolutional and transformer layers. The convolutional layers process the input text in chunks, whereas the transformer layers capture the relationships between different parts of the input text. A pooling layer is also included in the encoder, summarising the encoded text and sending it to the decoder.
The decoder comprises a series of transformer layers that produce the output text. The decoder generates the output text token by token based on the encoded input text. A masked language modeling (MLM) objective is included in the decoder, which encourages the model to predict the correct output token given the previous tokens.
Model Type: Language model
Language(s) (NLP): English, German, French, Romanian, and many more.
License: Apache 2.0


Training Details
Training data
Long T5 is trained on diverse text data in 24 languages, including Wikipedia, web pages, and books. The training data is preprocessed to convert to a text-to-text format, with each example containing a source text and a target text representing the desired output.


Training dataset size
The size of the training dataset is not stated explicitly in the paper. However, the authors state that they use a preprocessed dataset similar to the original T5 model and containing 37B tokens from various languages.
Training Procedure
Long T5 is pre-trained using a Masked Language Modeling (MLM) objective variant, where a certain percentage of tokens in the input sequence is randomly masked, and the model is trained to predict the masked tokens.
Training Observations
The Long T5 model was trained using a curriculum learning approach. Hyperparameter tuning and parallel training across multiple GPUs were implemented to achieve the best performance. Despite the computational difficulties, the Long T5 model showed the best results on several NLP benchmarks, including the LAMBADA and the SuperGLUE. benchmark.
Model Types
Several versions of the Long T5 model have been trained on the same dataset. Here are the variations of the Long T5 model based on parameter count:
| Model | Parameters | Highlights |
| LongT5-Local-Base | 250 million | Text classification, language modeling |
| LongT5-TGlobal-Base | 250 million | Question answering, summarization, translation |
| LongT5-Local-Large | 780 million | Text classification, language modeling |
| LongT5-TGlobal-Large | 780 million | Question answering, summarization, translation |
| LongT5-TGlobal-XL | 3 billion | Question answering, summarization, translation |
Model Task
Below are some important tasks of the model Long T5.
Machine Reading Comprehension
The CNN/Daily Mail dataset is used for machine reading comprehension tasks; when given a news article and a set of related questions, the task is to answer the questions. The Long T5 language model trained on this dataset can be used for reading comprehension, question answering, and information retrieval tasks.
Scientific Paper Summarization
The arXiv dataset is used for scientific paper summarization tasks. The Long T5 language model trained on this dataset can be used for tasks such as text summarization, information retrieval, and machine translation in the scientific domain.
Biomedical Text Mining
The PubMed dataset is used for biomedical text-mining tasks. The Long T5 language model trained on this dataset can be used for tasks such as named entity recognition, relationship extraction, and text classification in the biomedical domain.
Patent Summarization/strong>
The BigPatent dataset is used for patent summarization tasks. The Long T5 language model trained on this dataset can be used for tasks such as text summarization, information retrieval, and machine translation in the patent domain.
News Article Summarization
The MediaSum dataset is used for abstractive summarization tasks on news articles. The Long T5 language model trained on this dataset can be used for tasks such as text summarization, information retrieval, and machine translation in the news domain.
Multi-Document Summarization
The Multi-News dataset is used for multi-document summarization tasks, where given a set of news articles, the task is to generate a summary that covers the main points from all the articles. The Long T5 language model trained on this dataset can be used for tasks such as text summarization, information retrieval, and machine translation in the news domain.
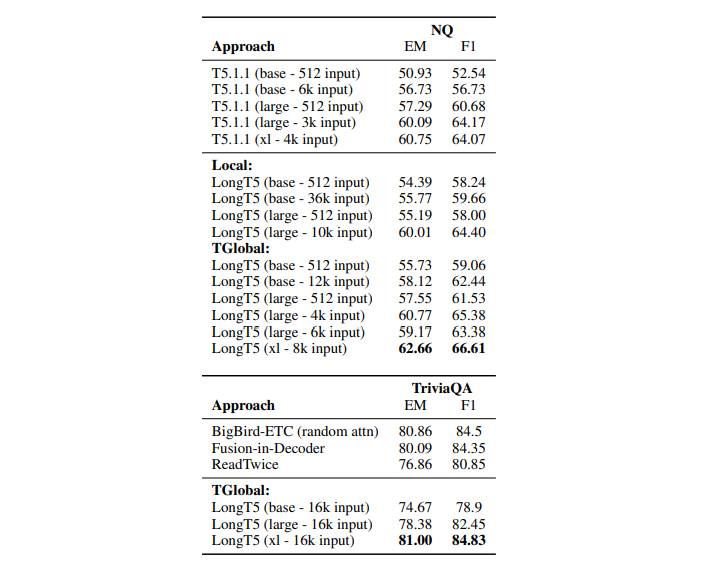
Question Answering on Long-Form Text
The NQ dataset is used for question-answering tasks on long-form text, such as Wikipedia articles. The Long T5 language model trained on this dataset can be used for reading comprehension, question answering, and information retrieval on long-form text.
Open-Domain Question Answering
The TriviaQA dataset is used for open-domain question-answering tasks. The Long T5 language model trained on this dataset can be used for reading comprehension, question answering, and information retrieval on general knowledge questions.