Llama 2
Llama 2 is a collection of pretrained and fine-tuned large language models (LLMs) that range in scale from 7 billion to 70 billion parameters. The fine-tuned LLMs, known as Llama 2-Chat, are specifically optimized for dialogue applications. These models surpass the performance of most open-source chat models on the benchmarks they were tested on.
Model Details100+ Technical Experts

50 Custom AI projects
4.8 Minimum Rating
An Overview of Llama 2
The architecture of LLAMA 2 is very similar to the first Llama, with the addition of Grouped Query Attention.

LLAMA 2 have double the context length than Llama 1
Trained on 2 trillion tokens
Llama 2's pretraining utilized an extensive 2 trillion-token dataset from publicly available content. It's fine-tuning involved publicly accessible instructional datasets and over a million new human-annotated examples.
Grouped Query Attention (GQA) to improve inference scalability.
Grouped Query Attention
LLAMA 2 used Grouped Query Attention to improve inference scalability. GQA is a standard practice for autoregressive decoding to cache the key and value pairs for the previous tokens in the sequence, speeding up attention computation.
The model uses a new method, GAtt for multi-turn consistency
Ghost Attention (GAtt)
The model uses Ghost attention for multi-turn consistency after RLHF (Context Distillation to remember previous/initial instructions). It is a novel method for forcing LLMs to follow instructions
Blockchain Success Starts here
Model Details
LLAMA 2 offers significant performance enhancements compared to its predecessor and has the added advantage of commercial usage rights. Llama 2 consists of a series of pretrained and fine-tuned LLMs that span from 7 billion to 70 billion parameters. Its model structure is akin to LLaMA 1 but boasts an extended context length and incorporates Grouped Query Attention (GQA) to enhance inference scalability. GQA is commonly employed in autoregressive decoding to store the key and value pairs of preceding tokens in a sequence, which accelerates attention computation. The model is training on 2 trillion tokens of data, Have an expanded context length of 4K and introduces a novel technique for multi-turn consistency named Ghost Attention (GAtt)


Training Details
Training Data
A new mix of publicly available online data is used for pretraining. All models are trained with a global batch-size of 4M tokens. Bigger models - 70B -- use Grouped-Query Attention (GQA) for improved inference scalability. Llama 2 is a static model trained on an offline dataset.


Training Infrastructure
Custom training libraries, Meta's Research Super Cluster, and production clusters were utilized for pretraining. The processes of fine-tuning, annotation, and evaluation were carried out on third-party cloud computing platforms.
Training Cost
Pretraining involved a total of 3.3M GPU hours of computation using A100-80GB hardware (with a TDP ranging from 350-400W). The estimated emissions amounted to 539 tCO2eq, and Meta's sustainability program offset 100% of these emissions.
Training Evaluation
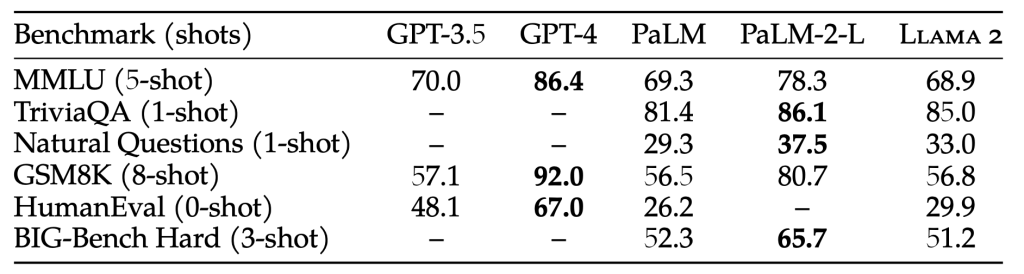
Average scores are presented for HumanEval, MBPP, and multiple benchmarks in areas like Commonsense Reasoning, World Knowledge, Reading Comprehension, and MATH. The breakdown includes 7-shot results, 0-shot, , 5-shot and distinct shot counts.
| Model | Size | Code | Commonsense Reasoning | World Knowledge | Reading Comprehension | Math | MMLU | BBH | AGI Eval |
| Llama 1 | 7B | 14.1 | 60.8 | 46.2 | 58.5 | 6.95 | 35.1 | 30.3 | 23.9 |
| Llama 1 | 13B | 18.9 | 66.1 | 52.6 | 62.3 | 10.9 | 46.9 | 37.0 | 33.9 |
| Llama 1 | 33B | 26.0 | 70.0 | 58.4 | 67.6 | 21.4 | 57.8 | 39.8 | 41.7 |
| Llama 1 | 65B | 30.7 | 70.7 | 60.5 | 68.6 | 30.8 | 63.4 | 43.5 | 47.6 |
| Llama 2 | 7B | 16.8 | 63.9 | 48.9 | 61.3 | 14.6 | 45.3 | 32.6 | 29.3 |
| Llama 2 | 13B | 24.5 | 66.9 | 55.4 | 65.8 | 28.7 | 54.8 | 39.4 | 39.1 |
| Llama 2 | 70B | 37.5 | 71.9 | 63.6 | 69.4 | 35.2 | 68.9 | 51.2 | 54.2 |
Llama 2 7B and 30B models outperform MPT models of the corresponding size in all categories besides code benchmarks. For the Falcon models, Llama 2 7B and 34B outperform Falcon 7B and 40B models on all categories of benchmarks. Additionally, Llama 2 70B model outperforms all open-source models.
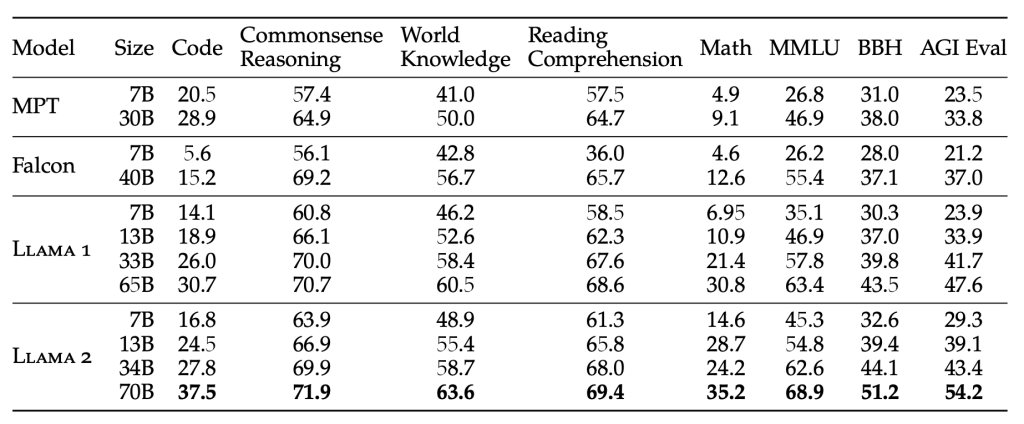
When compared with closed-source LLMs, Llama 2 70B is close to GPT-3.5 on MMLU and GSM8K, but there is a significant gap in coding benchmarks. Llama 2 70B results are on par or better than PaLM (540B) on almost all benchmarks. There is still a large gap in performance between Llama 2 70B and GPT-4 and PaLM-2-L.