




LLMs Explained,
Cerebras-GPT
Cerebras, a Silicon Valley AI company released Cerebras-GPT to provide an alternative to the tightly controlled and proprietary systems available today. The models are trained using 16 CS-2 systems in their Andromeda AI supercomputer with 111 million, 256 million, 590 million, 1.3 billion, 2.7 billion, 6.7 billion, and 13 billion parameters. The company released the pre-trained models and code and claimed that Cerebras-GPT is the first open and reproducible work comparing compute-optimal model scaling to models trained on fixed dataset sizes.
Model Card100+ Technical Experts

50 Custom AI projects
4.8 Minimum Rating
An Overview of Cerebras-GPT
Cerebras-GPT models are trained on the Eleuther Pile dataset following DeepMind Chinchilla scaling rules for efficient pre-training

Better accuracy than similar-sized publicly-available models
Improved Accuracy
Publisher claims that Cerebras-GPT 13B model shows improved accuracy on most downstream tasks compared to other similar-sized publicly-available models.
Improves the compute-optimal frontier loss by 0.4 percentage
Improved Frontier Loss
The models are configured using µP, enabling direct hyperparameter transfer from smaller to larger models and improving the compute-optimal frontier loss by 0.4%.
Model loss is expected to be ∼1.2% better than GPT-NeoX 20B.
Better than GPT-NeoX
If the model is trained with FLOPs equivalent to GPT-NeoX 20B, the publisher expects the Cerebras-GPT model loss to be ∼1.2% better than GPT-NeoX 20B.
Blockchain Success Starts here
About Model
Cerebras-GPT is an autoregressive transformer similar to GPT-2 and GPT-3. The model has a hidden size of 5,120. It has 40 layers and a head size of 128. The filter size is 20,480, and The context (sequence) length is 2,048. The model is trained from randomly initialized weights and the base variant uses standard parameterization initialization. The model is released under the Apache 2.0 license. Model is evaluated using text prediction cross-entropy on upstream tasks and text generation accuracy on downstream tasks. Moreover, due to limited computing resources, the model was not evaluated for prediction uncertainty or calibration. Variability analysis was only performed for small variants of Cerebras-GPT models using multiple runs from different random initializations and data loader seeds to assess variance in task performance.


Training Details
Training data
Cerebras-GPT is trained on the Pile dataset. Pile was cleaned using ftfy library to normalize text, and then filtered using scripts provided by Eleuther. Then, data was tokenized with byte-pair encoding using the GPT-2 vocabulary.


Preprocessing
Preprocess of the Pile dataset using tools and instructions from Eleuther and the community. Publisher clean the raw text using the ftfy library to normalize text and remove corrupted unicode. Our tokenized version of the Pile training set contains roughly 371B tokens. We find that shuffling samples across all training set documents improves validation loss by 0.7-1.5% compared to shuffling within a window of a few thousand documents.
Training Hardware
Cerebras-GPT is trained on the Pile dataset using Andromeda AI Supercomputer: Cerebras Wafer-Scale Cluster with 16 Cerebras CS-2 systems.
Evaluation Data
Upstream (pre-training) evaluations were completed using the Pile validation and test set splits. Downstream evaluations were performed on standardized tests. Cloze and completion tasks: LAMBADA, HellaSwag. Common Sense Reasoning tasks: PIQA, ARC, OpenBookQA. Winograd schema type tasks: Wino-grande. Downstream evaluations were performed using the Eleuther lm-eval-harness.
Model Types
Here are the variations of the PaLM-Emodel based on parameter count:
| Model | Parameters |
| PaLM-E-12B | 12 Billion |
| PaLM-E-66B | 66 Billion |
| PaLM-E-84B | 84 Billion |
| PaLM-E-562B | 562 Billion |
Table below shows the performance of T5 variants on various tasks.
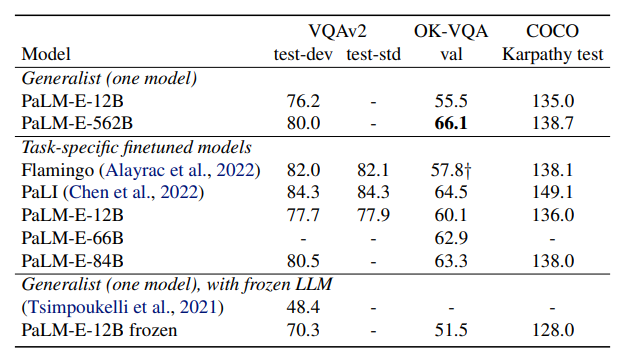
" Results on general visual-language tasks. For the generalist models, they are the same checkpoint across the different evaluations, while task-specific finetuned models use differentfinetuned models for the different tasks. COCO uses Karpathy splits. † is 32-shot on OK-VQA (not fine-tuned)."
"PaLM-E-562B model achieves the highest reported number on OK-VQA, including outperforming models fine-tuned specifically on OK-VQA. Compared to (Tsimpoukelli et al., 2021), PaLM-E achieves the highest performance on VQA v2 with a frozen LLM to the best of our knowledge. This establishes that PaLM-E is a competitive visual-language generalist, in addition to being an embodied reasoner on robotic tasks."
