LLMs Explained,
Flan T5
Flan T5 is a large-scale pre-trained transformer-based language model developed by Google. It is designed to perform natural language processing (NLP) tasks, such as text classification, sentiment analysis, and question answering. Flan T5 is among Google's largest models based on the T5 architecture. It has been pre-trained on massive data and can be fine-tuned for various NLP tasks.
Model Card100+ Technical Experts

50 Custom AI projects
4.8 Minimum Rating
An Overview of Flan T5
Flan T5's architecture allows for easy adaptation to new tasks and domains, making it a flexible tool for various natural language processing applications.

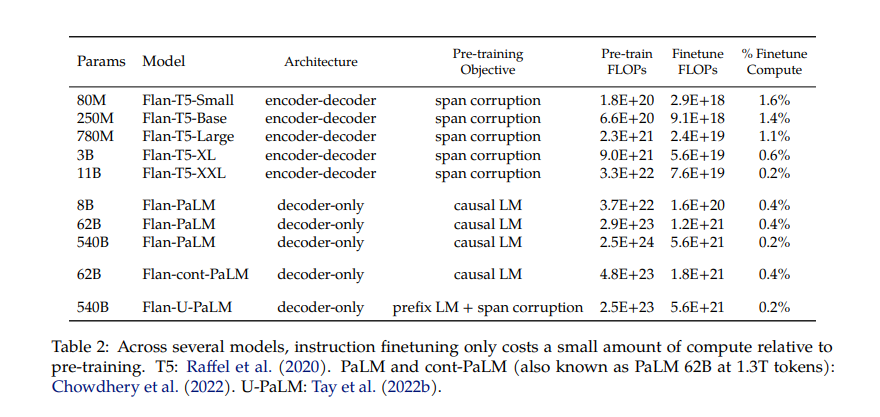
Fine-tuned on 1.8K tasks using the standard T5 architecture
1.8K tasks
Flan-T5 was fine-tuned on 1.8K tasks, using the standard T5 architecture with 12 transformer layers and a sequence length of 512.
Flan-T5 XXL has 11 billion parameters
11B parameters
Flan-T5 XXL has 11 billion parameters, making it one of the largest publicly available language models.
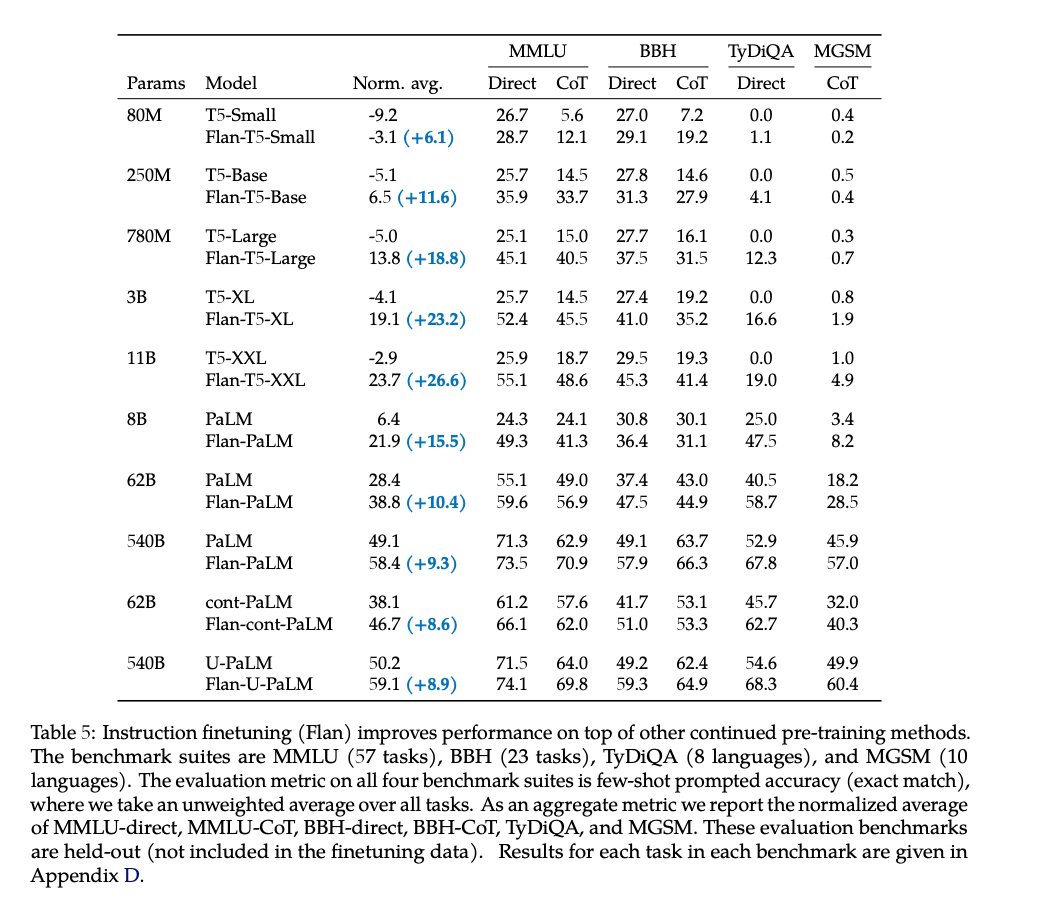
Flan-T5 11B outperforms T5 11B by double-digit improvements
Outperforms T5
Flan-T5 11B outperforms T5 11B by double-digit improvements and also outperforms PaLM 62B on some challenging BIG-Bench tasks.
Blockchain Success Starts here
About Model
Google created Flan T5, a transformer-based language model. It is based on the T5 architecture and has 12 transformer layers and a feed-forward neural network to process text in parallel. The model is one of Google's largest, with over 20 billion parameters and pre-trained on massive data sets such as web pages, books, and articles. Flan T5 comes in various sizes and is used for various NLP tasks such as text classification, summarization, and question-answering. The model is pre-trained with the BERT-style objective, where it learns to predict masked tokens, and is trained with a denoising autoencoder to capture the text's semantics.
Model Type: Transformer-based language model
Language(s) (NLP): English, German, and French.
License: Apache 2.0


Training Details
Training data
Flan T5 is pre-trained on a large amount of text data, which includes web pages, books, articles, and other sources in multiple languages. The pre-training data is curated to cover various domains and


Training dataset size
The paper does not provide information on the exact size of the pre-training dataset for Flan T5. However, it is noted that the pre-training data is massive, and the model is pre-trained using the T5 architecture.
Training Procedure
The training procedure for Flan T5 involves two stages: pre-training and instruction finetuning. The pre-training stage is done using the T5 architecture, and it involves training the model to predict the next token in a sequence given the previous tokens. Finetuning instruction involves training the model on a collection of instruction datasets to improve its performance and generalization to unseen tasks.
Training time and resources
The paper does not provide detailed information on the training time and resources used to train Flan T5. However, it is noted that the model is pre-trained using Google's proprietary TPU (Tensor Processing Unit) hardware, which is specifically designed for deep learning workloads and can provide significant speedups compared to traditional hardware.
| Model | Parameters |
| Flan-T5-Small | 80 million |
| Flan-T5-Base | 250 million |
| Flan-T5-Large | 780 million |
| Flan-T5-XL | 3 billion |
| Flan-T5-XXL | 11 billion |
| Multi-task Language Understanding | Cross-Lingual Question Answering |
| Chatbots and virtual assistants | Customer support and service in multilingual environments |
| Sentiment analysis and customer feedback analysis | Business intelligence and analytics across international markets |
| Content summarization and generation | Multilingual search engines and content indexing |
| Personalized recommendations and advertising | Translation and localization services |
| Document classification and information extraction | Language learning and education platforms |