



LLMs Explained,
GLM 130B
GLM is a General Language Model pretrained with an autoregressive blank-filling objective and can be finetuned on various natural language understanding and generation tasks. The model is trained on a diverse and extensive corpus of text data. GLM-130B, with 130 billion parameters, has demonstrated cutting-edge performance in various language tasks, including question-answering, sentiment analysis, and machine translation. On a wide range of tasks across Natural Language Understanding, conditional and unconditional generation, GLM outperforms BERT, T5, and GPT on common testing conditions.
Model Details100+ Technical Experts

50 Custom AI projects
4.8 Minimum Rating
An Overview of GLM
GLM's largest variant, GLM-130B, is a large-scale language model with 130 billion parameters, trained on a diverse and extensive corpus of text data.

GLM has variants' parameter range from 110M to 130B
130B parameters
Largest GLM, GLM-130B, is a pre-trained language model developed with 130 billion parameters. It can capture complex linguistic patterns and nuances.
GLM-130B is trained on English as well as Chinese.
Bilingual Lang Model
GLM-130B is also evaluated on Chinese benchmarks as a bilingual LLM with Chinese. Trained on 1.0T Chinese WudaoCorpora, and 250G Chinese corpora.
GLM-130B outperforms ERNIE TITAN 3.0
Outperforms ERNIE TITAN
GLM-130B consistently outperforms ERNIE Titan 3.0 (largest Chinese LLM). Model outperforms ERNIE by at least 260% on two abstractive MRC datasets.
Blockchain Success Starts here
Model Details
GLM is a General Language Model pretrained with an autoregressive blank-filling objective and can be finetuned on various natural language understanding and generation tasks. Its largest variant, GLM-130B, with 130 billion parameters, is trained on a diverse and extensive corpus of text data. GLM-130B has achieved state-of-the-art performance on various language tasks, including question-answering, sentiment analysis, and machine translation. GLM-130B uses a transformer-based architecture similar to other large-scale language models such as GPT-3. It is a dense bidirectional model pre-trained with over 400 billion tokens on a cluster of 96 NVIDIA DGX-A100 (840G) GPU nodes. GLM-130B outperforms GPT-3 175B on a wide range of popular English benchmarks, while the performance advantage is not observed in OPT-175B and BLOOM-176B. It also consistently and significantly outperforms ERNIE TITAN 3.0 260B, the largest Chinese language model across related benchmarks.
Model Type: Transformer-based language model with autoregressive blank infilling
Language(s): English, Chinese
License: GLM: MIT license, GLM-130B: Apache-2.0


Training Details
Training data
The pre-training data includes 1.2T Pile English corpus, 1.0T Chinese WudaoCorpora, and 250G Chinese corpora, including online forums, encyclopedia, and QA crawled from the web, which forms a balanced composition of English and Chinese contents.


Training infrastructure
GLM-130B is trained on a cluster of 96 DGX-A100 GPU (8×40G) servers with 60-day access. During this period, the publisher managed to train GLM-130B for 400 billion tokens with a fixed sequence length of 2,048 per sample.
Training Objective
GLM-130B pre-training objective includes the self-supervised GLM autoregressive blank infilling and multi-task learning for a small portion of tokens. This is expected to help boost its downstream zero-shot performance.
Training Observation
The training period spanned two months. The publisher managed to reach the INT4 weight quantization for GLM-130B. The INT4 version of GLM-130B without post-training faces negligible performance degradation compared to its uncompressed original.
| Model | Parameters |
| GLM-Base | 110 Million |
| GLM-Large | 335 Million |
| GLM-Large-Chinese | 335 Million |
| GLM-Doc | 335 Million |
| GLM-410M | 410 Million |
| GLM-515M | 515 Million |
| GLM-2B | 2 Billion |
| GLM-10B | 10 Billion |
| GLM-10B-Chinese | 10 Billion |
| GLM-130B | 130 Billion |
Benchmark Results
Benchmarking is an important process to evaluate the performance of any language model, including GLM-130B. The key results are;
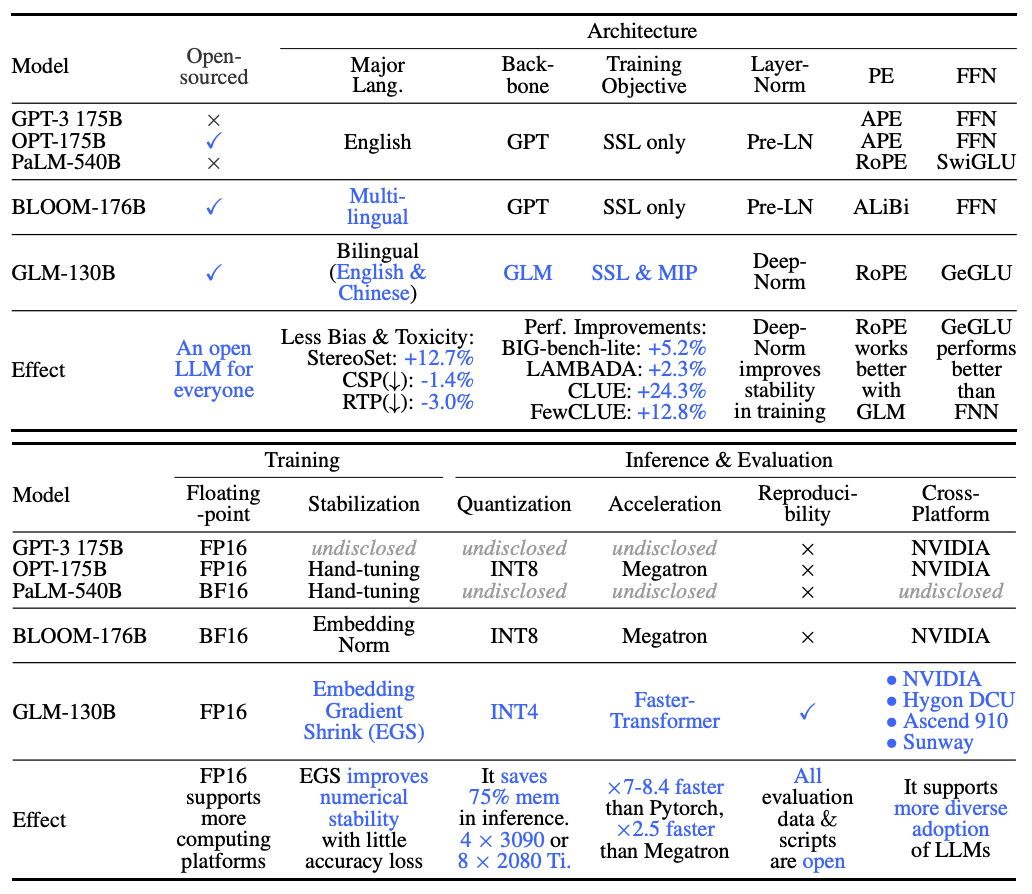
A comparison between GLM-130B and other 100B-scale LLMs and PaLM 540B. (SSL: self-supervised learning; MIP: multi-task instruction pre-training; (A)PE: (absolute) positional encoding; FFN: feed-forward network)
